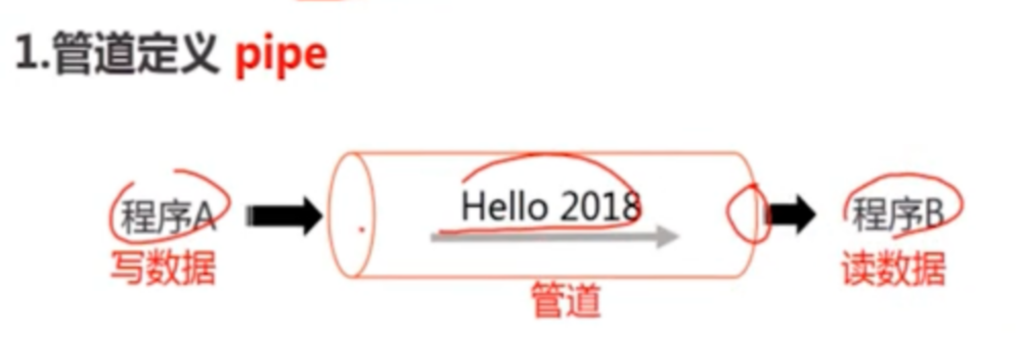
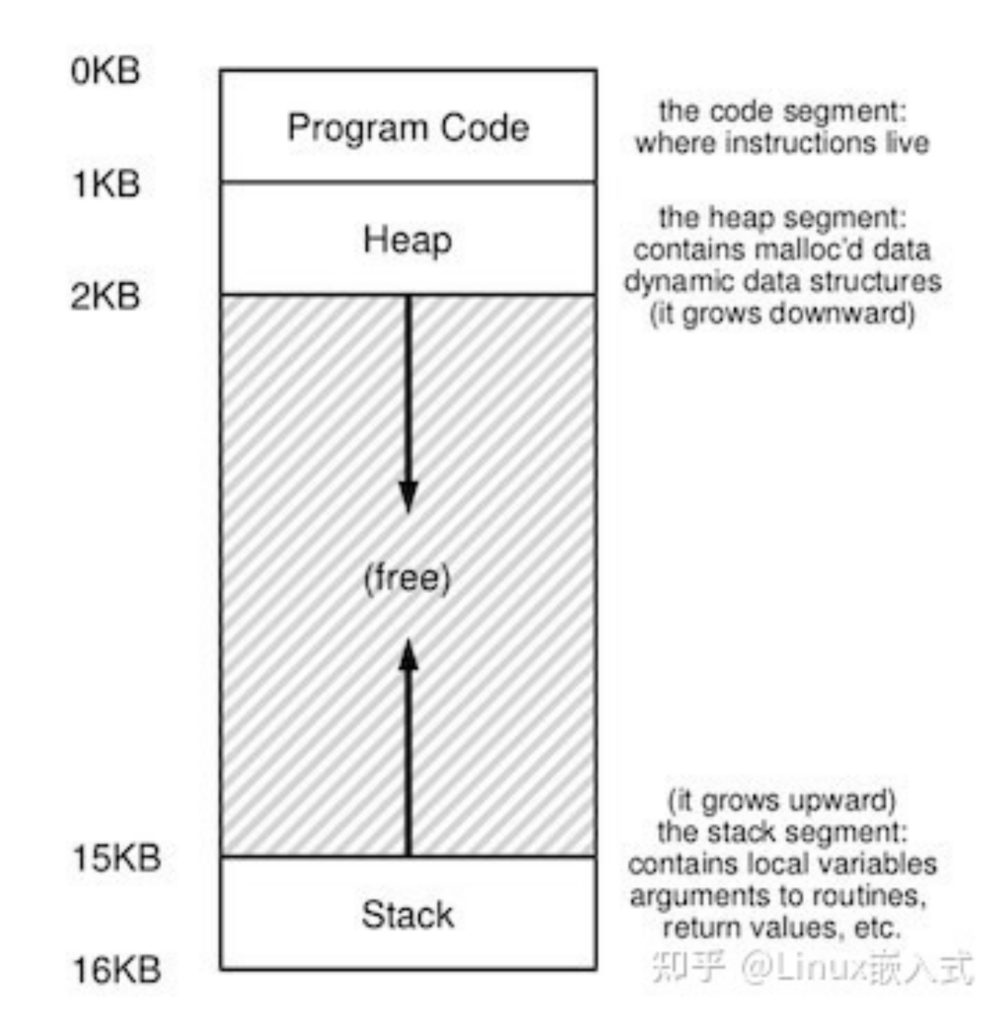
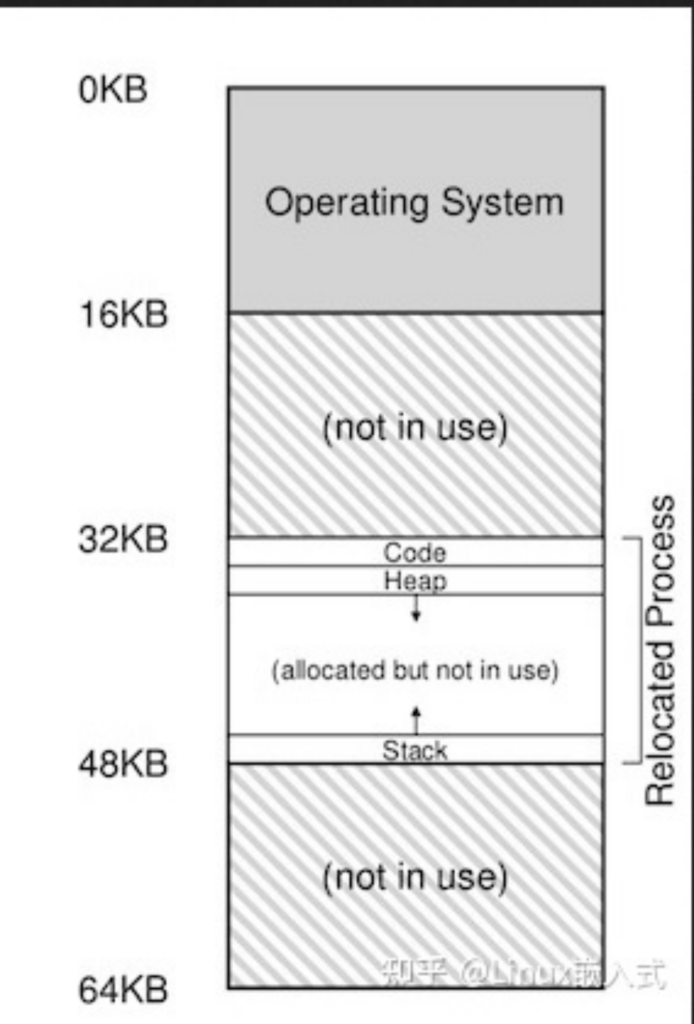
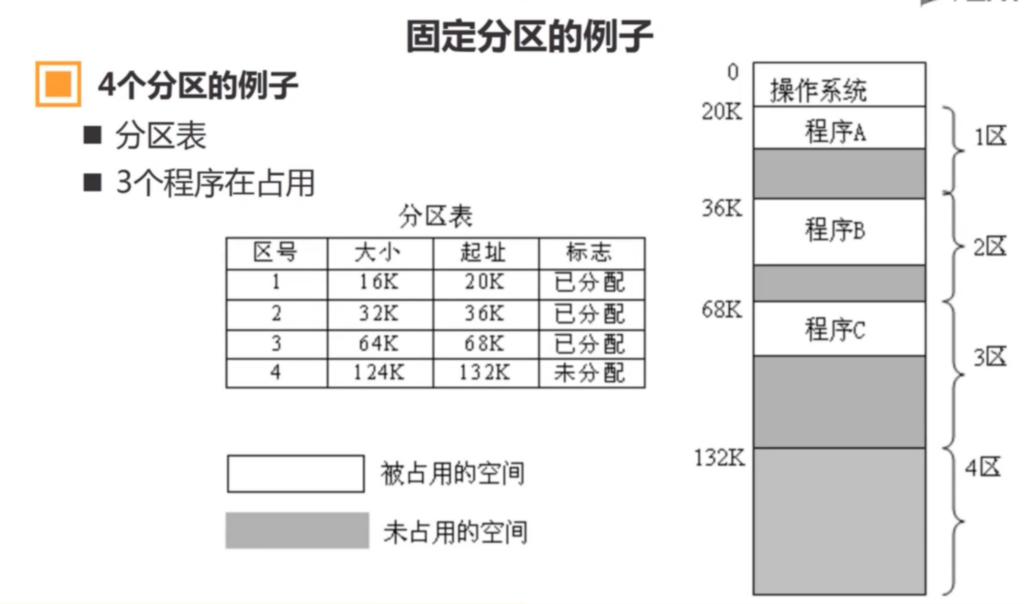
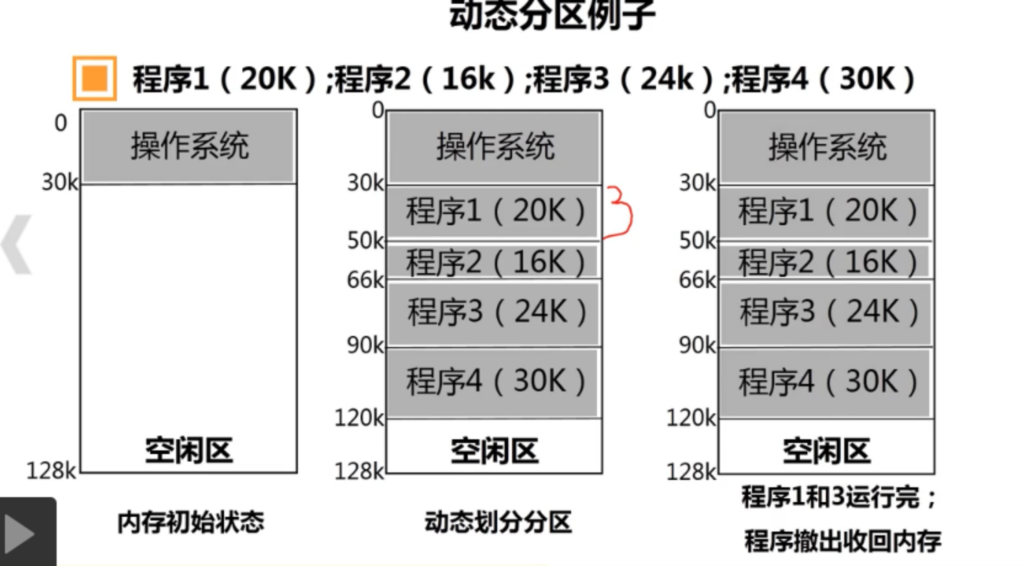
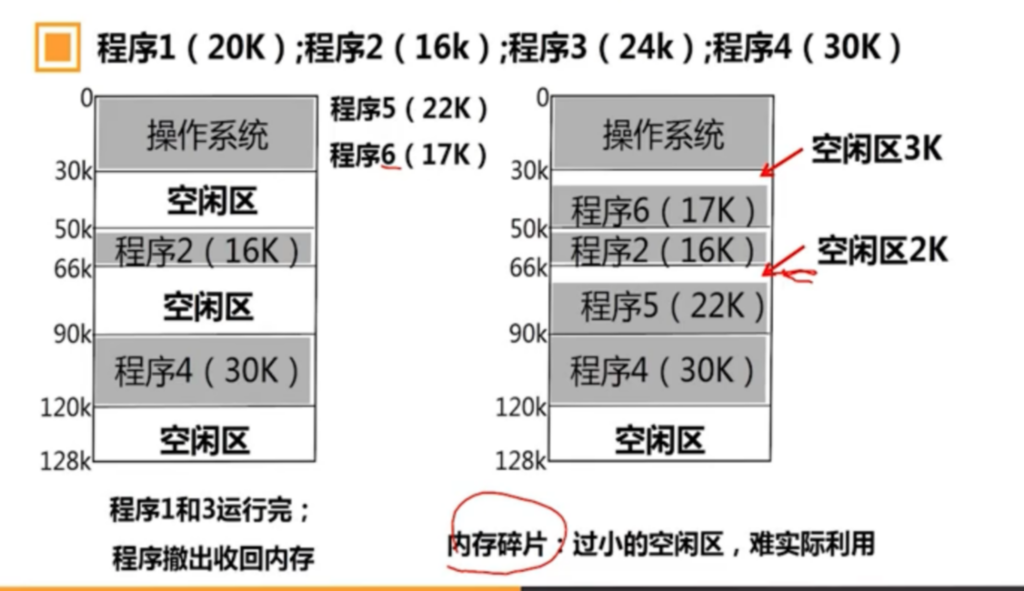
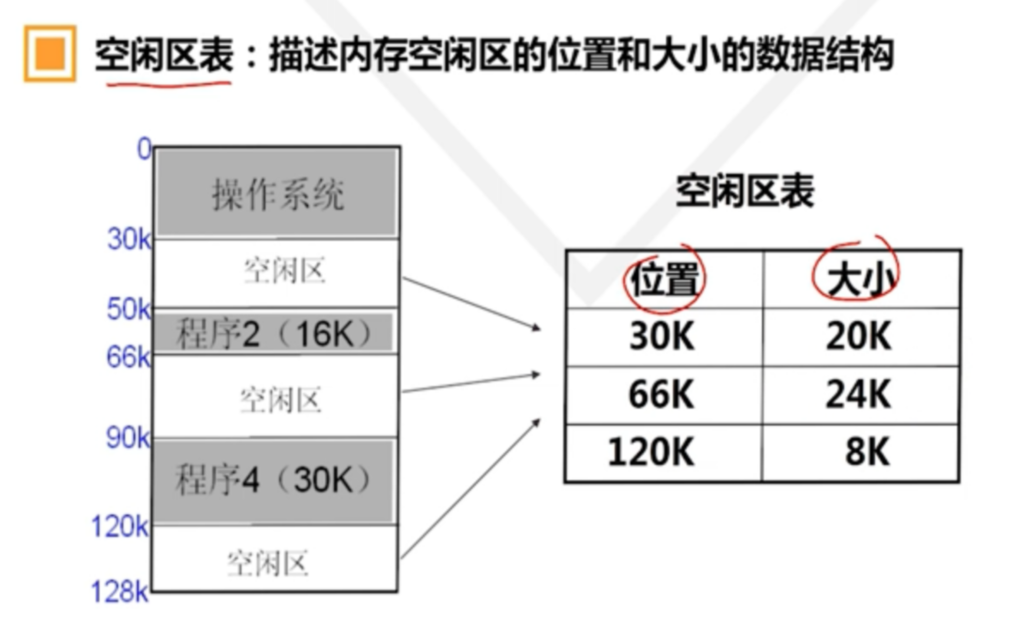
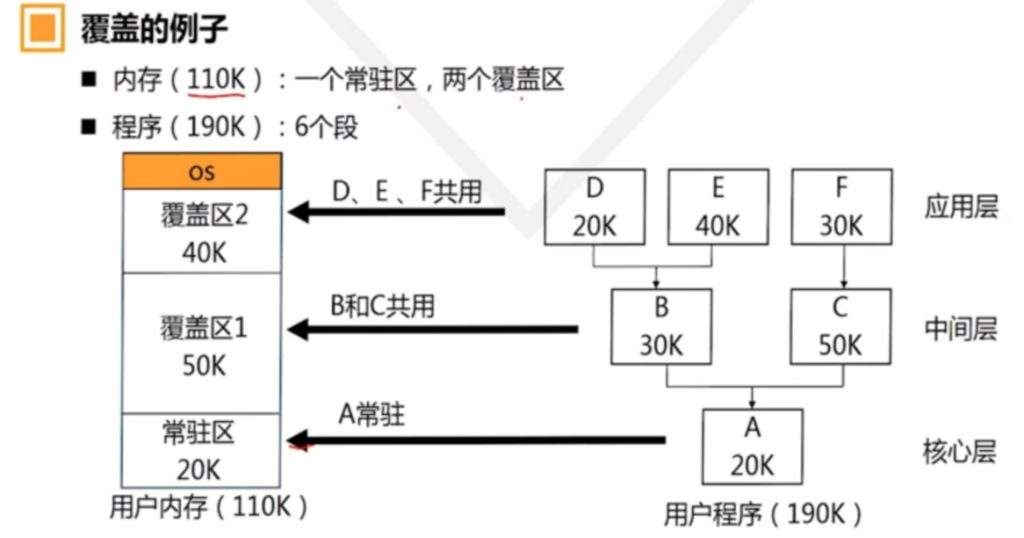
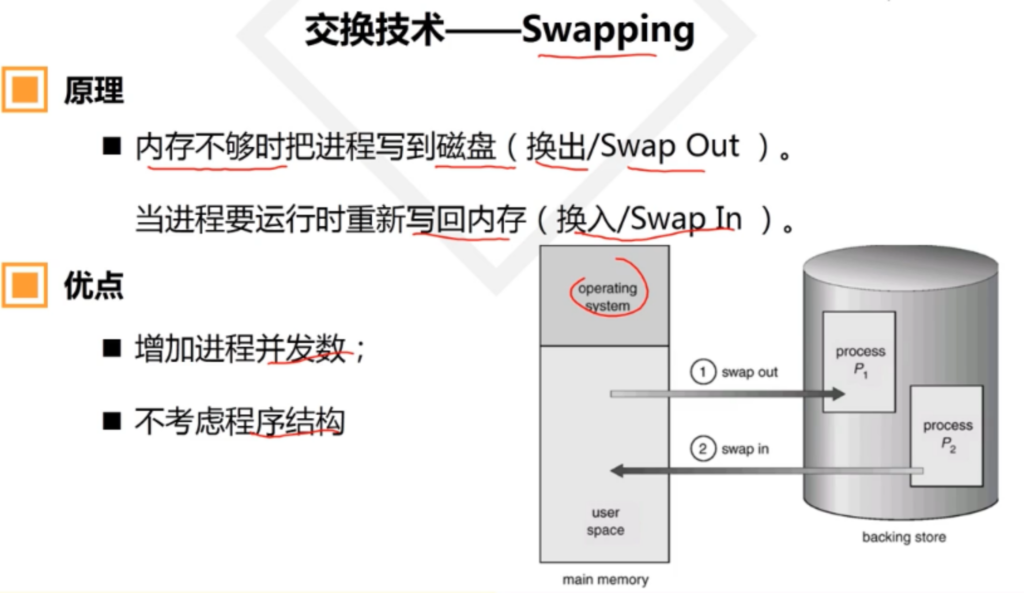
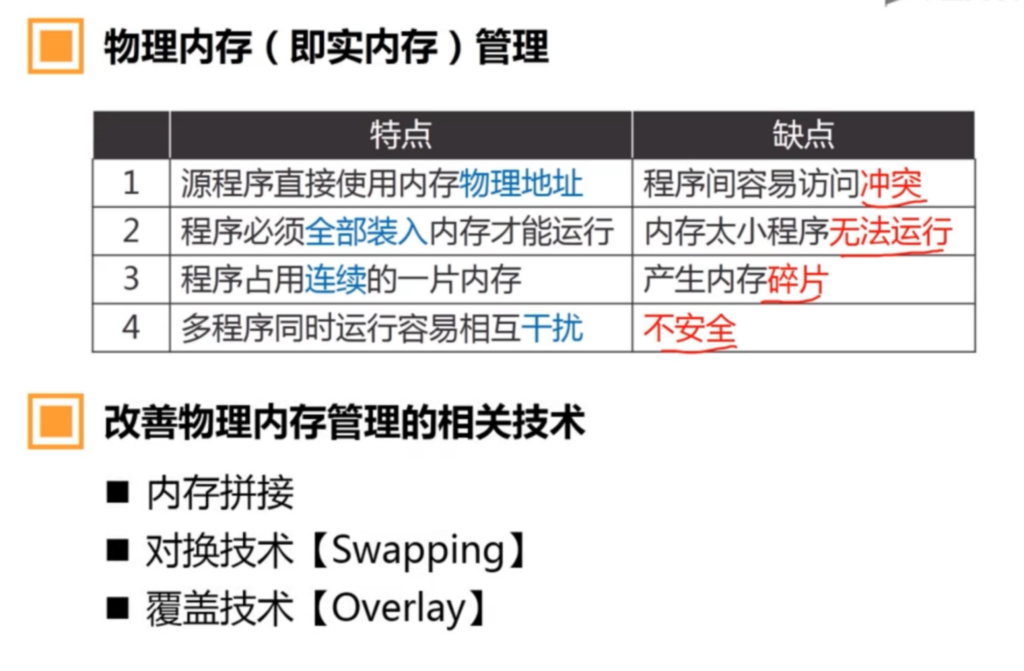
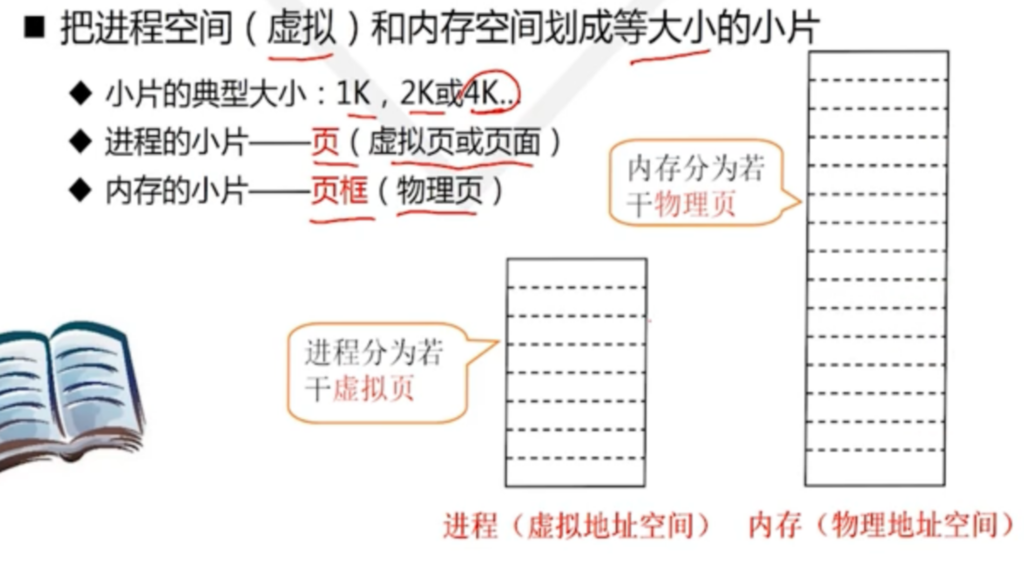
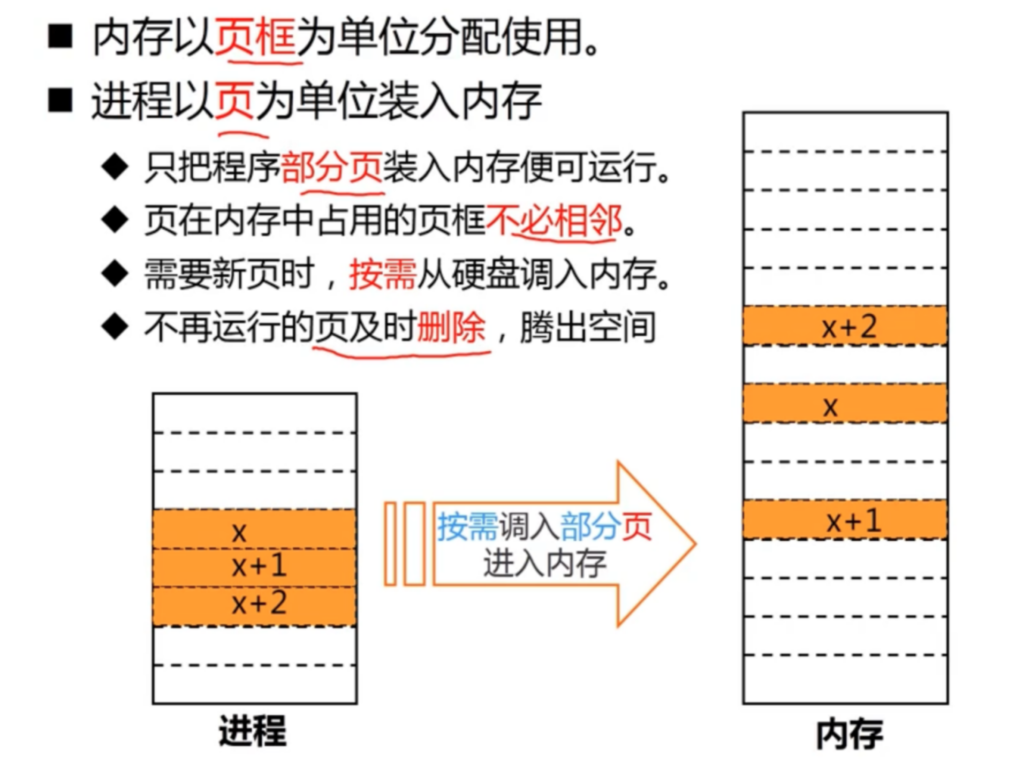
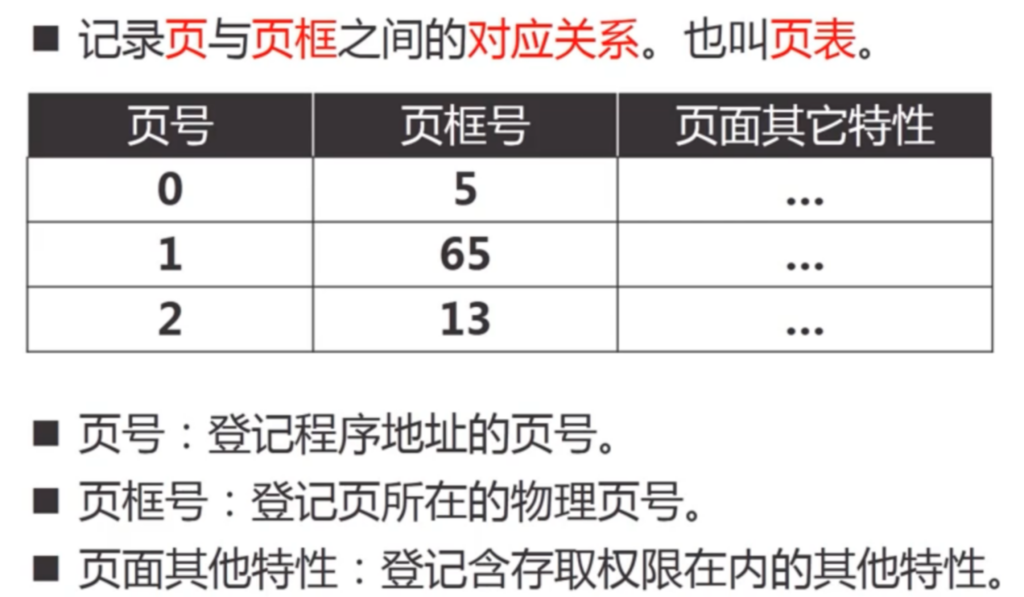
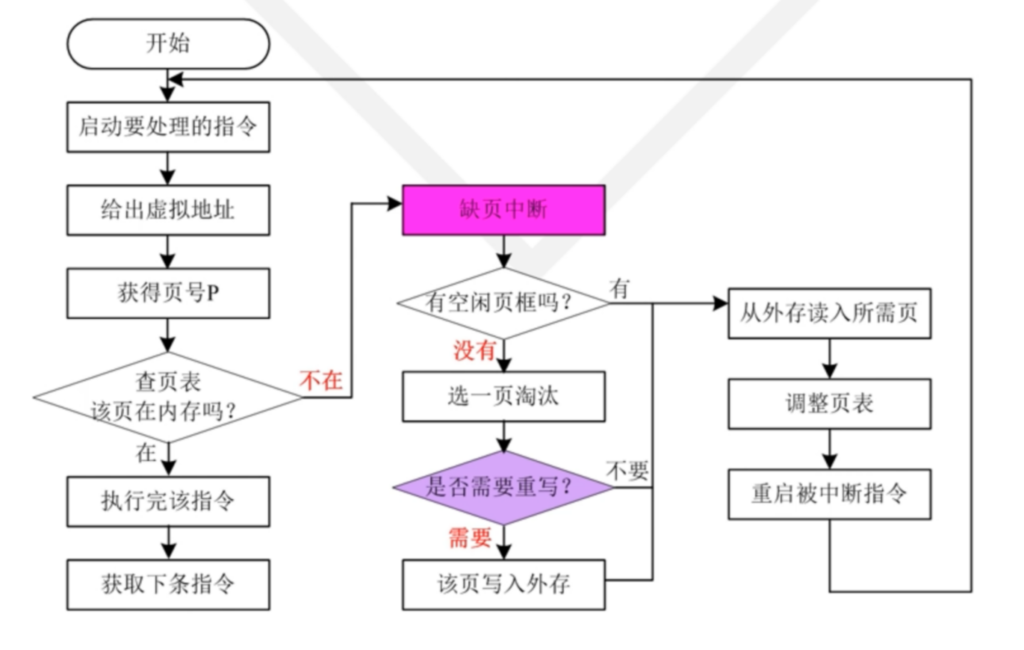
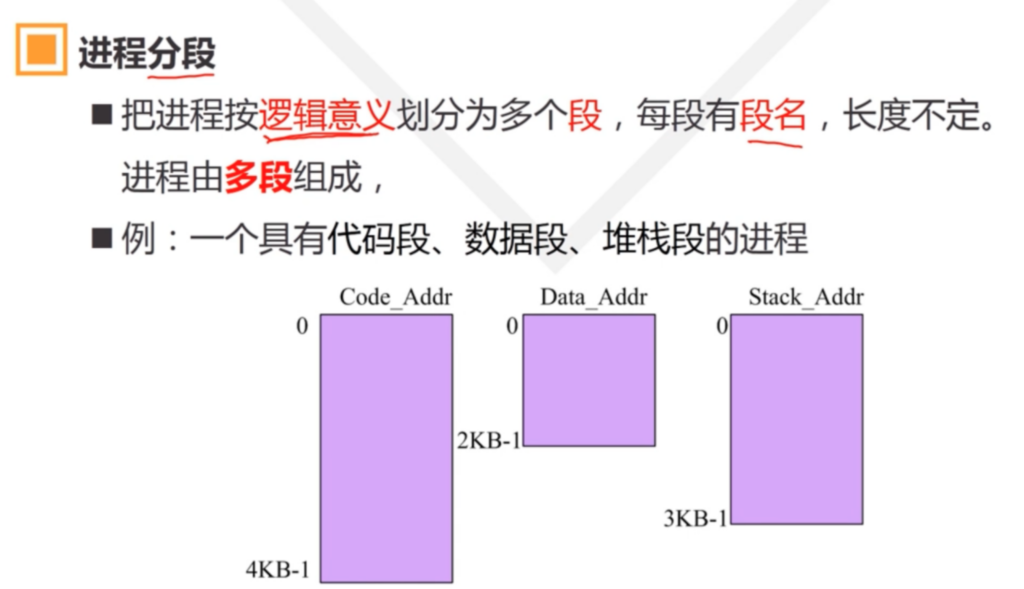
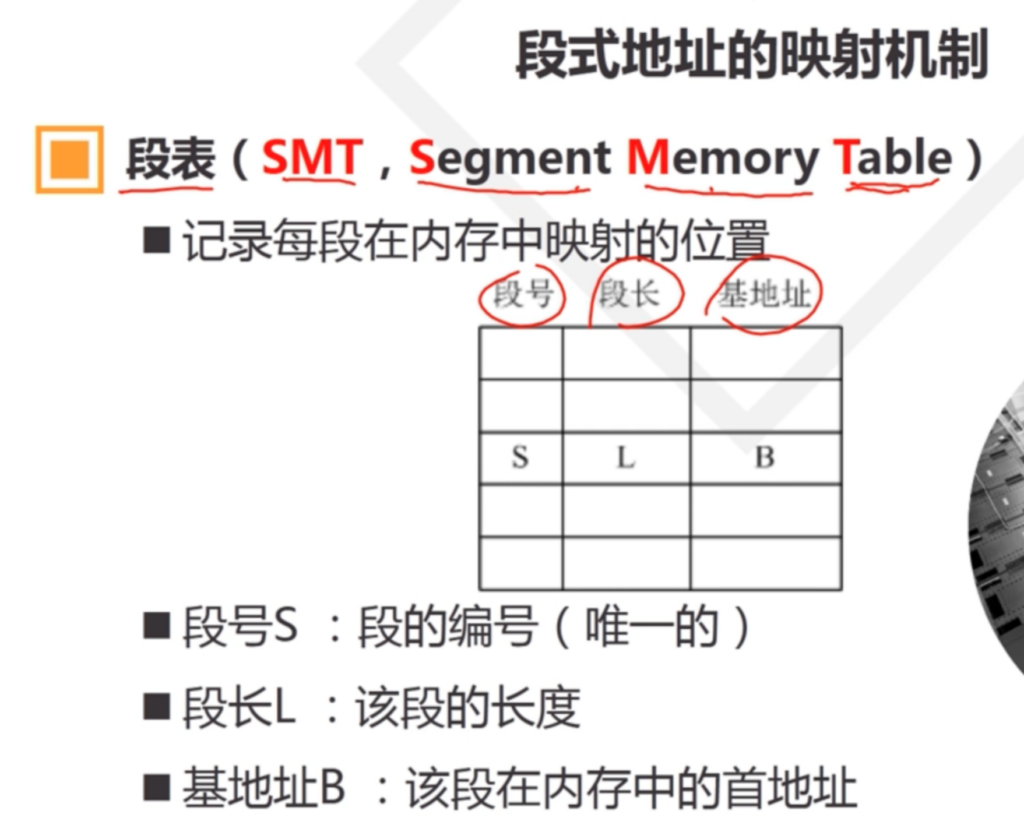
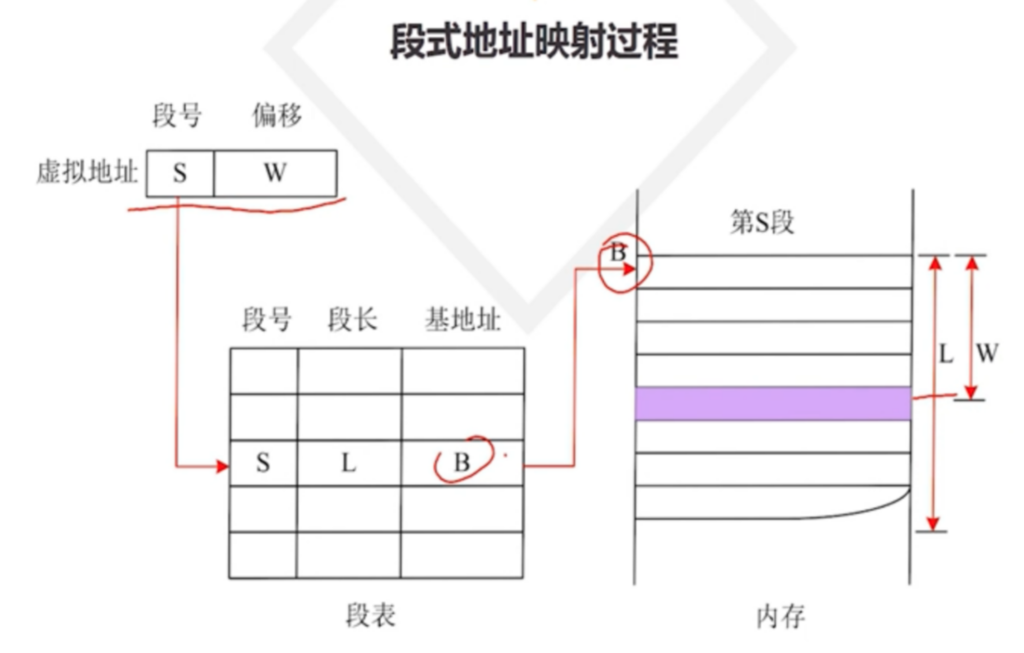
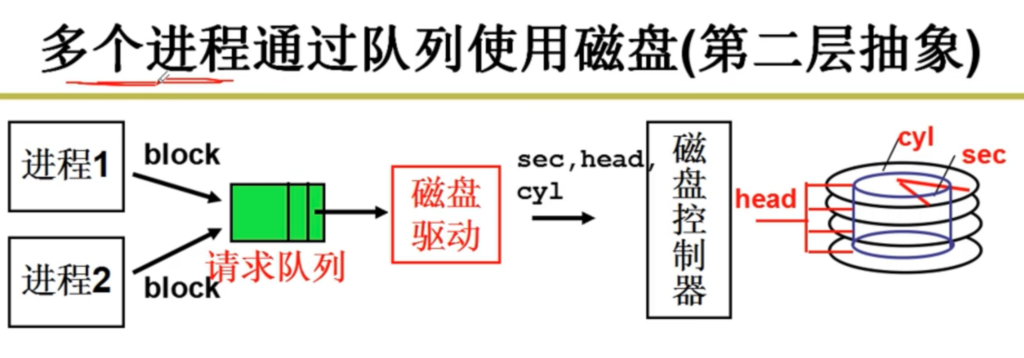
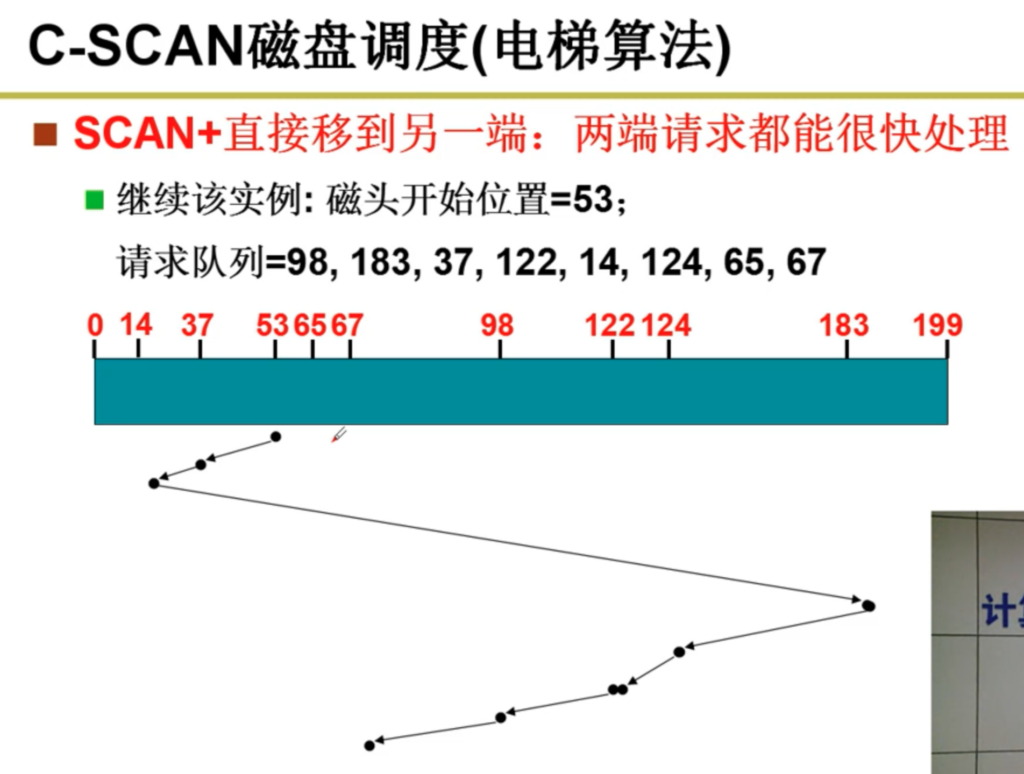
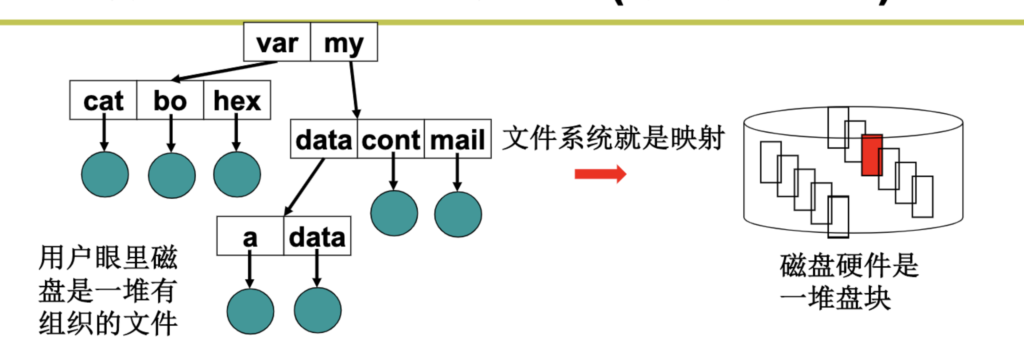
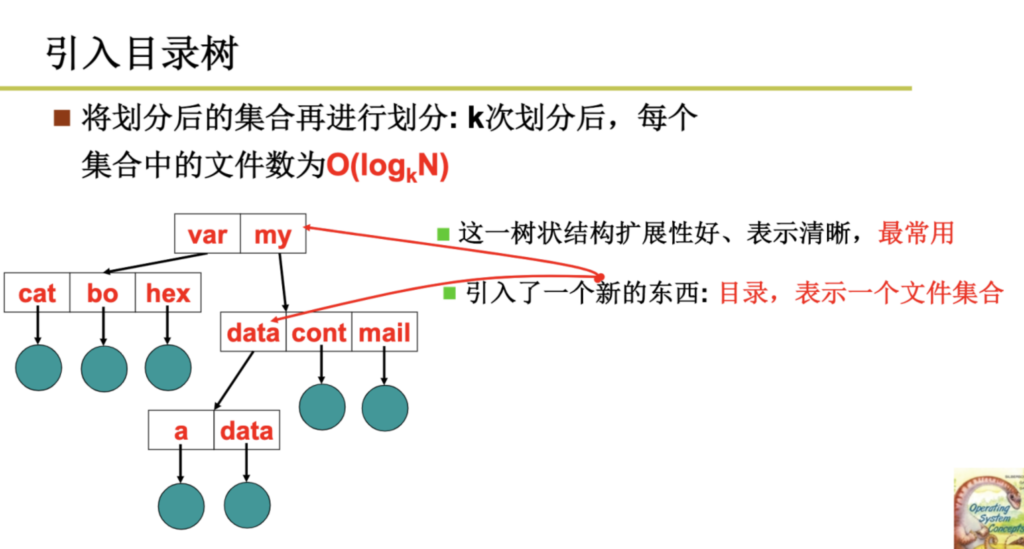
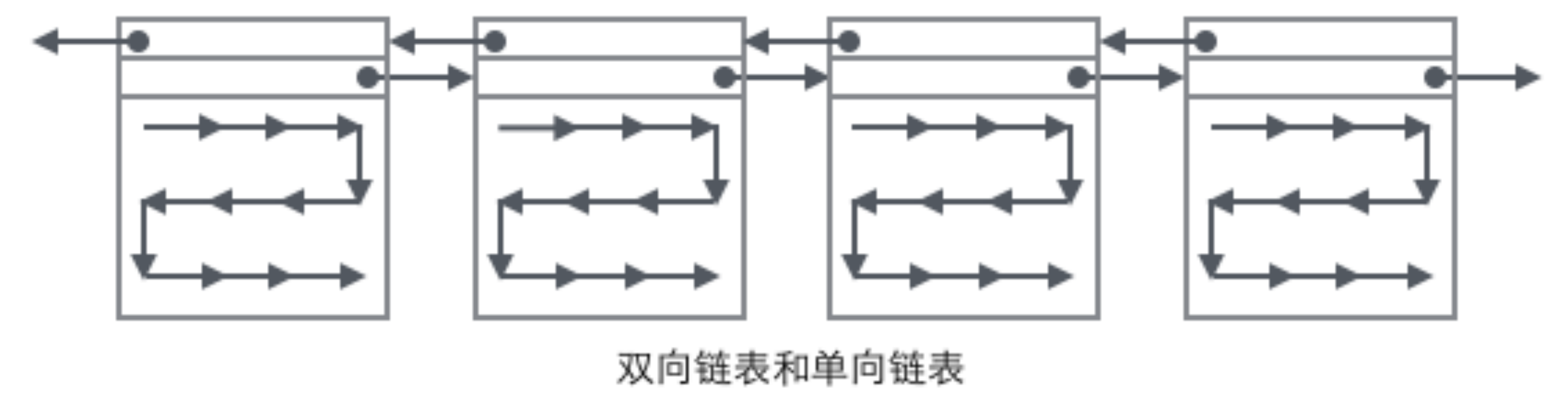
在这种管理方式中,内存被分为两个区域:系统区和用户区。应用程序装入到用户区,可使用用户区全部空间。其特点是,最简单,适用于单用户、单任务的操作系统。CP/M和 DOS 2.0以下就是采用此种方式。这种方式的最大优点就是易于管理。但也存在着一些问题和不足之处,例如对要求内存空间少的程序,造成内存浪费;程序全部装入,使得很少使用的程序部分也占用—定数量的内存。
Athena makes it is easier to get started and is more flexible in the types of data it can query, but performance is not guaranteed without significant data preparation
基于数据库架构的数据仓库
这种就是Redshift,BigQuery, SnowFlake这些架构特点,会对数据进行预处理,也会利用一些常用的数据库技术,例如Amazon Redshift is a cloud data warehouse optimized for analytics performance,on PostgreSQL。StarRocks跟面试官交流是基于Mysql的。
对比Athena和Redshift:Redshift requires DBA resources to manage and resize clusters; with Athena there is no infrastructure to manage.
一个更典型的例子:
Hive VS Redshift:
Hadoop Hive can roughly be understood as an attempt to get Hadoop’s distributed file system and MapReduce structure to behave more like a traditional data warehouse by allowing data analysts to run SQL-like queries on top of Hadoop. The queries, written in HiveQL, are translated into MapReduce jobs written in Java and are run on the Hadoop Distributed File System.
Tests have shown that Redshift can be 5x to 20x faster than Hadoop Hive on the same dataset.
Since Redshift is a columnar database, the data must be structured, and this will mean faster querying over any unstructured data source. Moreover, since Redshift uses a Massively Parallel Processing architecture, the leader node manages the distribution of data among the follower nodes to optimize performance.
Number of mentions of the system on websites, measured as number of results in search engines queries. At the moment, we use Google and Bing for this measurement. In order to count only relevant results, we are searching for <system name> together with the term database, e.g. “Oracle” and “database”.
General interest in the system. For this measurement, we use the frequency of searches in Google Trends.
Frequency of technical discussions about the system. We use the number of related questions and the number of interested users on the well-known IT-related Q&A sites Stack Overflow and DBA Stack Exchange.
Number of job offers, in which the system is mentioned. We use the number of offers on the leading job search engines Indeed and Simply Hired.
Number of profiles in professional networks, in which the system is mentioned. We use the internationally most popular professional network LinkedIn.
Relevance in social networks. We count the number of Twitter tweets, in which the system is mentioned.
Relational database management systems (RDBMS) support the relational (=table-oriented) data model. The schema of a table (=relation schema) is defined by the table name and a fixed number of attributes with fixed data types. A record (=entity) corresponds to a row in the table and consists of the values of each attribute. A relation thus consists of a set of uniform records.
The table schemas are generated by normalization in the process of data modeling.
Certain basic operations are defined on the relations:
classical set operations (union, intersection and difference)
Selection (selection of a subset of records according to certain filter criteria for the attribute values)
Projection (selecting a subset of attributes / columns of the table)
Join: special conjunction of multiple tables as a combination of the Cartesian product with selection and projection.
These basic operations, as well as operations for creation, modification and deletion of table schemas, operations for controlling transactions and user management are performed by means of database languages, with SQL being a well established standard for such languages.
CREATE TEMPORARY TABLE top10customers
SELECT p.customerNumber,
c.customerName,
FORMAT(SUM(p.amount),2) total
FROM payments p
INNER JOIN customers c ON c.customerNumber = p.customerNumber
GROUP BY p.customerNumber
ORDER BY total DESC
LIMIT 10;
现在,可以从top10customers临时表中查询数据,例如:SELECT * FROM top10customers;
Windows 和 Linux 下的 MySQL 配置文件的名字和存放位置都是不同的,WIndows 下 MySQL 配置文件是 `my.ini` 存放在 MySQL 安装目录的根目录下;Linux 下 MySQL 配置文件是 `my.cnf` 存放在 `/etc/my.cnf`、`/etc/mysql/my.cnf`
当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14″这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
So now let me start with what is happening on the master. For replication to work, first of all master needs to be writing replication events to a special log called binary log. This is usually very lightweight activity (assuming events are not synchronized to disk), because writes are buffered and because they are sequential. The binary log file stores data that replication slave will be reading later.
Whenever a replication slave connects to a master, master creates a new thread for the connection (similar to one that’s used for just about any other server client) and then it does whatever the client – replication slave in this case – asks. Most of that is going to be (a) feeding replication slave with events from the binary log and (b) notifying slave about newly written events to its binary log.
Slaves that are up to date will mostly be reading events that are still cached in OS cache on the master, so there is not going to be any physical disk reads on the master in order to feed binary log events to slave(s). However, when you connect a replication slave that is few hours or even days behind, it will initially start reading binary logs that were written hours or days ago – master may no longer have these cached, so disk reads will occur. If master does not have free IO resources, you may feel a bump at that point.
MySQL expire_logs_days 参数用于控制Binlog文件的保存时间,当Binlog文件存在的时间超过该参数设置的阈值时,Binlog文件就会被自动清除,该参数的时间单位是天,设置为0,表示Binlog文件永不过期,即不自动清除Binlog文件。在MySQL 8.0 版本,该参数被废弃,使用新的参数binlog_expire_logs_seconds代替,新参数的时间粒度是秒,能够更加灵活的控制Binlog文件过期时间。
Elasticsearch’s data replication model is based on the primary-backup model and is described very well in the PacificA paper of Microsoft Research. That model is based on having a single copy from the replication group that acts as the primary shard. The other copies are called replica shards. The primary serves as the main entry point for all indexing operations. It is in charge of validating them and making sure they are correct. Once an index operation has been accepted by the primary, the primary is also responsible for replicating the operation to the other copies.