
(转载请注明作者和出处‘https://fourthringroad.com/’,请勿用于任何商业用途)
资料:
- 博文视点-《kubernetes in Action》
- 网络视频课程
- 参考资料
基础概念
什么是云原生:
先看看官方定义
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
简而言之,云原生就是在多种云环境中,构建高可用,弹性伸缩,方便管理和监控的应用。
CNCF(Cloud Native Computing Foundation):
云原生计算基金会,Linux旗下非盈利基金会。谷歌容器编排技术Borg(k8s前身)开源后与Linux共同成立了CNCF。致力于推动云原生相关技术的发展。
云原生的技术:
参考CNCF的路线图(trail map),主要和代表技术为:
- 容器化:docker
- CI/CD(Continuous Integration / Delivery):Argo
- 编排:k8s+helm
- 监控&分析:Prometheus for monitoring, Fluentd for logging, Jaeger for tracing
- 服务代理(proxy),发现(discovery),治理(mesh):CoreDNS, Envoy, Linkerd
- 网络和安全:Calico, Flannel, OPA, Falco
- 分布式数据库和存储:Vitess(可分片的mysql),etcd, TiKV
- 流处理&消息处理
- 容器镜像库和运行环境:Harbor(私有镜像仓库)
- 软件发布
参考CNCF的全景图(landscape),可以了解更多的项目,包括已经毕业的,孵化中的,CNCF成员自己的项目。。。等等。
云原生应用的特性(什么是云原生应用)
TBD
回顾容器化发展:
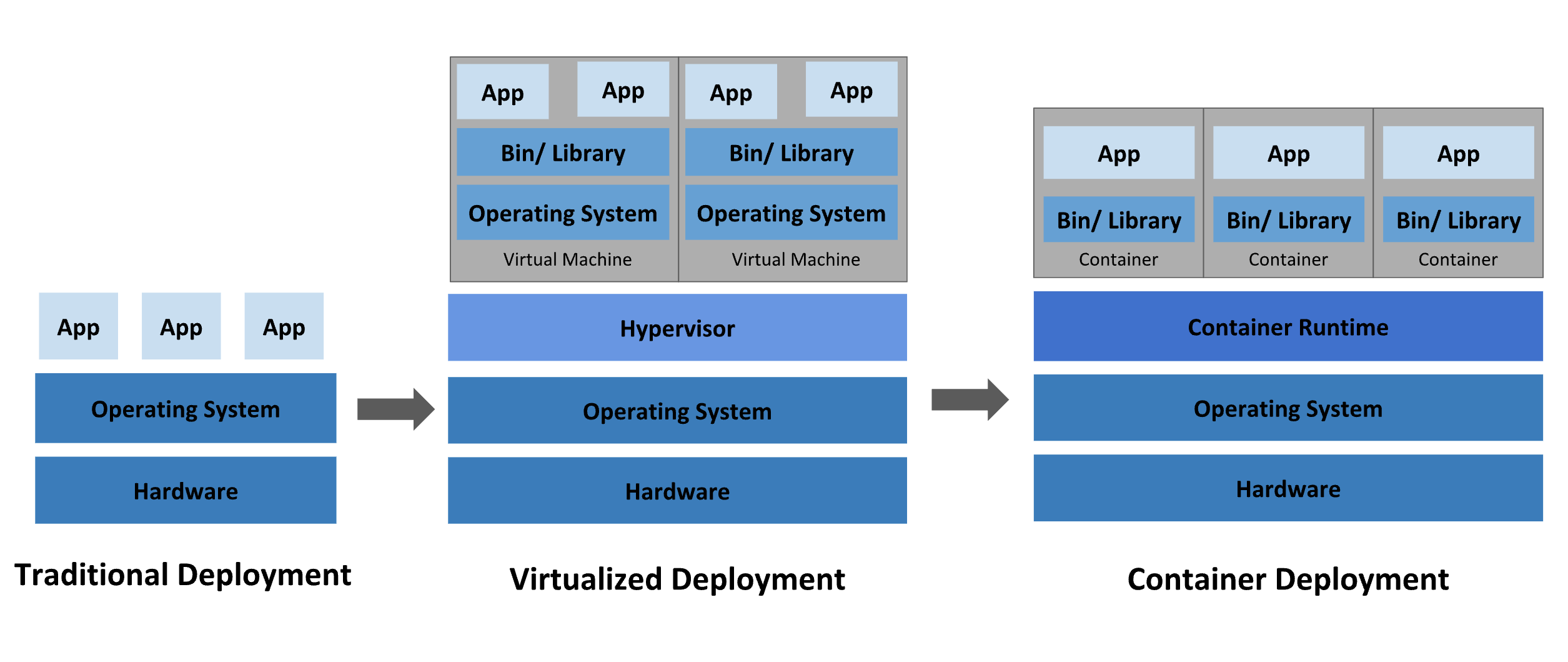
物理机部署的缺点是:资源不存在边界,隔离性差,扩展费用昂贵。
虚拟机部署:解决物理机部署的缺点
容器化部署:共享OS,相比VM更轻量级
k8s发展背景:
Kubernetes(k8s): 希腊语舵手(helmsman)所以logo是一个舵哈哈
可以看出K8s只是云原生版图中的一部分,是一个容器编排系统(Container Ochestration):
无论是基于云架构,还是基于企业内部的物理机/虚机资源池,容器化已经成为广泛采纳的部署技术,但是容器资源的管理,调度,编排是复杂的问题,所以出现了一些解决方案,譬如Mesos,K8s,Swarm。
例如我司中间件云服务的就是基于就是在IaaS上的一个k8s集群,用户的请求会通过我们的控制层传达到k8s集群,进行相关资源的管理调度和编排。
K8s特性:
- Automated rollouts and rollbacks
- Service discovery and load balancing
- Storage orchestration
- Secret and configuration management
- Resource Management for Pods and Containers
- Batch Execution(基于jobs)
- IPv4 & IPv6 dual-stack
- Horizontal Scaling
- Self-healing
- Designed for Extensibility
K8s架构:
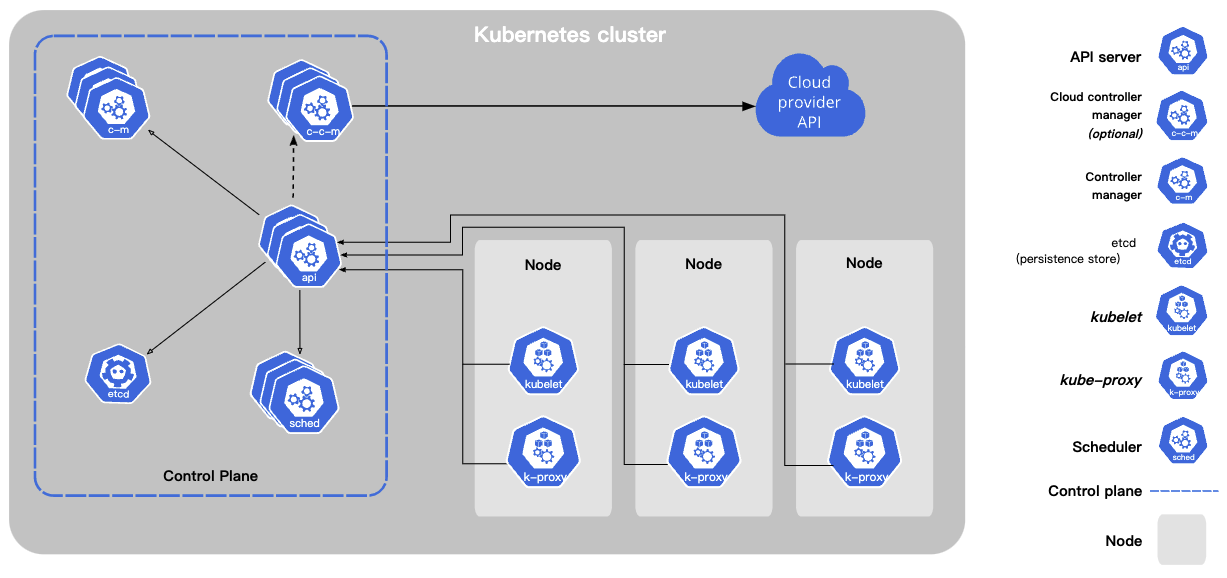
K8s采用了Master-Worker架构,master就是指图中的control plane控制平面,为了高可用通常也是一个集群。负责管理worker节点和上面的pods。Worker指上图的node节点,pod会部署在上面。
Control-plane的组件:
- Kube-api-server:暴露Kubernetes API,是对外的frontend;支持水平扩展。只有它与控制平面的各个组件通信。
- Etcd:高可用分布式键值数据库,存储集群信息;基于http+raft协议。
- Kube-Scheduler:负责调度pod到某个node上面;考虑的因素包括: individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines
- Kube-Controller-manager: 用来执行controller协程;后者是一个控制回路,通过api-server监控pod状态,并使其向期望状态发展
- Cloud-controller-manager:The cloud-controller-manager only runs controllers that are specific to your cloud provider;通过上图的 cloud provider’s API进行控制。
Node上的组件:
- Kubelet: 负责管理node上的pod(a set of containers)
- Kube-proxy: 负责网络请求转发;譬如,一系列的pod是通过service向外界提供服务,kube-proxy就是实现service的基础。
还有一些组件可以借助上述组件和k8s的机制进行安装,并且属于kube-system的名称空间下,为集群提供服务,例如CoreDNS。完整可询 https://kubernetes.io/docs/concepts/cluster-administration/addons/
K8s vs istio
TBD
GKE (Google Kubernetes Engine) vs K8S :
GKE是托管的k8s服务,out-of-box,多租户,类似的产品包括AWS的 Amazon Elastic Kubernetes Service (EKS)
K8s vs Mesos vs Swarm
TBD
Why etcd?
- 数据一致性
- 支持持久化
- 高可用
- 高性能
相关核心概念:
- Pod:k8s管理的最小单元,可以包括一至多个容器。
- 资源清单: 定义资源的yaml文件
- Controller:类似一个控制回路Control Loop,监控资源状态并向理想状态方向调整,例如ReplicaSet, StatefulSet, DaemonSet等等controllers。
- Operator: k8s的扩展性的体现,自定义资源类型(CRD)及开发对应的自定义controller。
- Service & Ingress:如何将一组pod以服务形式对外暴露
- Volume & PV:存储
- ConfigMap & Secret: 配置和密钥
- Scheduler: 如何进行pod的调度,故障域,亲和性,污点等概念
- Authentication & Authorization: 认证 与 鉴权。
工具:
- Helm:
- K9s:
关于API Server:
API Server暴露的HTTP接口,使用户与k8s集群,组件与组件之间得以相互通信。
用户有几个常用工具管理集群:restful api, kubectl,kubeadm,k9s。
Restful api是一切的基础,例如我们使用kubectl + yml时,实际上kubectl底层将信息转化为api+json的形式与api server进行通信。
其中restful api是基于OpenAPI规范设计的;后者是一个基于Yaml/json的Restful API设计规范。同时方便用户/机器理解,遵循OpenAPI规范设计的API可以利用工具校验,生成文档,生成多语言客户端等等。
关于k8s中的对象(object,也可以叫资源):
K8s中的一切资源都是对象,包括:pod, rs, deployment, job, service, ingress, volume, configmap, secrete,Namespace, node, role, clusterRole等等
有两个东西用来描述k8s中的实体:spec(资源清单)和status(状态);The Kubernetes control plane continually and actively manages every object’s actual state to match the desired state you supplied.
Namespace-名称空间:
保证对象(object)的隔离性:In Kubernetes, namespaces provides a mechanism for isolating groups of resources within a single cluster.
但是有些资源是跨namespace的,譬如role。
GVK vs GVR
GVK = GroupVersionKind,GVR = GroupVersionResource。
apiVersion:这个就是 GV 。
kind:这个就是 K。根据 GVK K8s 就能找到你到底要创建什么类型的资源,根据你定义的 Spec 创建好资源之后就成为了 Resource,也就是 GVR。GVK/GVR 就是 K8s 资源的坐标,是我们创建/删除/修改/读取资源的基础。
关于pods:
pod是最小部署单元,实际上是一组容器的集合,共享存储和网络资源。可以将pod理解成一个逻辑主机(logical host);pod中的容器共享存储(fs volumes)、网络和命名空间(namespaces)
如何通过kubectl启动一个pod:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
kubectl apply -f xxx.yaml通常不会直接创建一个pod(创建之后无人管理),而是通过controller,譬如deployment, ReplicaSet, statefulSet, job 等等。
一个pod可以包括多个containers,这些container可以共享资源(网络,存储),相互通信,例如sidecar pattern;当然必须要有合理的理由将这些containers结合在一起;否则就应该将他们部署在不同的pod中。
注:一个container内应当尽量只有一个进程。
pod中的共享资源:
- 存储:pod中的容器可以有共享卷
- 网络:每一个pod都类似一个逻辑主机,拥有一个唯一IP地址,其中的容器共享这个IP地址和网络端口。他们之间的通信可以直接通过localhost实现。然而单纯从dock儿容器角度讲,部署在同一台服务器上的容器间通信就更为复杂了:https://stackoverflow.com/questions/41093812/how-to-get-docker-containers-to-talk-to-each-other-while-running-on-my-local-hos;
Pause container:
之所以pod中的容器能够共享网络,是因为在创建pod之后,首先有一个隐藏的容器被创建了,pause container,之后的容器都会复用它的网络栈。
The ‘pause’ container is a container which holds the network namespace for the pod.
pod之间通信:
通过IP可以直接访问;每个pod(pause 容器)都有全局唯一的IP地址,并且构成一个扁平化的虚拟网络。所有的pod的IP地址资源和真实物理主机的路由关系是存储在etcd中的。
同一个node上pod间通信:走内部docker网桥
不同node上pod间通信有所不同:走物理网卡(src pod ip + src node ip -> dst pod ip + dst node ip)通过flannel实现
容器探针:
pod中的容器可以定义探针,可以周期性的被kubelet进行健康诊断,支持的探针类型:
- 容器操作
- Tcp socket请求
- http get 请求
静态pod:
Static Pods are always bound to one Kubelet on a specific node。kubelet直接管理的pod(而不是controller)。
容器&pod的生命周期:
pod的phase阶段:
- Pending:还在schedule,下载image等等
- Running:至少一个容器启动
- Succeeded:所有容器都成功停止
- Failed:所有容器都停止,而且至少一个是以失败状态停止的
- Unknown:For some reason the state of the Pod could not be obtained. This phase typically occurs due to an error in communicating with the node where the Pod should be running.
一个pod一旦被创建,就一定遵循上述几个阶段,不会出现类似reschedule到另一个node的状态。
Container的阶段:
Waiting, Running, and Terminated
Status
Pod启动之后更详尽的状态记录在它spec中的status下面,里面有资源在运行时的一些信息;
有下面一些内置的status:
- PodScheduled: the Pod has been scheduled to a node.
- ContainersReady: all containers in the Pod are ready.
- Initialized: all init containers have completed successfully.
- Ready: the Pod is able to serve requests and should be added to the load balancing pools of all matching Services.
Pod readiness:
在spec中设置readinessGates;允许用户向 Pod Status 中注入额外的自定义反馈或者信号;pod 中的所有 container 都ready并且所有 readinessGates 中定义的状态都是 ‘True’ 之后 Pod 才会被标记为 ready.
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 内置的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 额外的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: trueWhen a Pod’s containers are Ready but at least one custom condition is missing or False, the kubelet sets the Pod’s condition to ContainersReady.
探针机制:
A probe is a diagnostic performed periodically by the kubelet on a container
探针的形式:
- exec
- grpc
- httpGet
- tcpSocket
Readiness Probe -就绪探针
检测是否ready,只有ready才会被驾到Service后面的pod列表里并提供对外服务
Liveness Probe-生存探针
检测容器是否存活
Startup Probe – 启动探针
其他探针不会在startup探针成功之前启动。
Init 容器
A Pod can have multiple containers running apps within it, but it can also have one or more init containers, which are run before the app containers are started.
Init containers are exactly like regular containers, except:
- Init containers always run to completion.
- Each init container must complete successfully before the next one starts.
Init 容器有一些牛逼的地方,譬如:
- 包含一些运行时镜像中没有的依赖
- 权限可以与应用程序容器不同
例如,可以在init容器中循环检查一个外部依赖是否ready,ready才启动pod;如果超时则exit 1;
Container Lifecycle Hooks
容器在启动后和结束前都有一个hook:PostStart/PreStop
控制器
所谓控制器就是一个control loop-控制回路,官方给了一个调温器的例子来说明:
When you set the temperature, that’s telling the thermostat about your desired state. The actual room temperature is the current state. The thermostat acts to bring the current state closer to the desired state, by turning equipment on or off.
contollers都运行在kube-controller-manager上。
A Kubernetes Controller is a routine;一个控制器本质上是一个go 协程;
控制器获取信息,发送指令都是通过API Server间接完成。
CRI: Container Runtime Interface
一个非常重要的模块。Container Runtime是从容器系统中剥离出来专门运行容器的软件功能。K8s为了兼容多种container runtime,抽象出了一层CRI;kubelet 通过cri直接管理容器的运行。
标签和注解
pod上的label标签用于selector进行选择;
pod上的annotation注解用于为pod提供更多的信息。
Owner reference
Owner reference 告诉控制平面某一个对象依赖另外的哪一个对象。Kubernetes uses owner references to give the control plane, and other API clients, the opportunity to clean up related resources before deleting an object. In most cases, Kubernetes manages owner references automatically.
例如,一个RS创建的pod,如果用yaml格式查看:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-02-12T07:06:16Z"
generateName: frontend-
labels:
tier: frontend
name: frontend-b2zdv
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: frontend
uid: f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...
RC-ReplicationController(deprecated)
A ReplicationController ensures that a specified number of pod replicas are running at any one time
Example:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80保证label selector匹配的pod数量和replicas中的一样
RS-ReplicaSet
增强版本的RC,selector 的表达能力更起强,譬如支持:匹配缺少某个label的pod,包含某个特定label的pod而不管其值如何。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3Deployment
不直接管理pod,而是管理RS,方便滚动更新/部署,回滚,扩缩容。滚动更新时,实际上是创建一个新的RS来间接控制新的pod的创建。
实现零停机升级的手段包括蓝绿部署,滚动部署;
早期的滚动部署可以通过kubectl来直接执行
Kubectl rolling-update xx-pod ….
但是这种由客户端发起的包含多条命令的流程有明显的缺点,及一旦中间client和master之间的网络出现问题,集群相关的对象可能会陷入一个中间状态;所以更理想的方式是‘声明’一个状态,交给k8s集群,让集群自己去完成工作。
声明式/命令式
声明式,告诉系统,系统会自主去实现;隐藏了底层的复杂逻辑。
例子
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80HPA:horizontal pod autoscaling
支持按照cpu,内存等使用率来自动扩缩容。底层通过RS间接控制Pod的数量
StatefulSet:
与Deployment和RS不同;它是针对有状态服务的pod管理。譬如一个pod要挂PVC则需要使用StatefulSet;支持按照顺序的扩缩容(pod按照0,1,2,3…的顺序扩容,相反顺序缩容);Pod重新调度后网络标志不变(主机域名不会变换,ip会变)。
STS中的pod的名称为 “container名称+序号”;例如:xx-0, xx-1, xx-3
STS中的每个pod都有自己的域名,可通过DNS解析,不需要直接通过IP地址调用;地址格式为’pod_name.headless_svc_name’;pod飘移时IP会变,但是域名不会变;
STS必须配合无头服务来使用;直接访问无头服务(dig),可以拿到所有pod的IP地址;
典型的例子,ES的集群就需要用Sts进行管理。
DaemonSet:
在node上运行一个守护pod。比如每个node上都要收集日志,就可以通过这个pod来执行。
Job/Cron Job
批处理/定时任务
You need to run a full 12 weeks on those priligy cvs
Почему торт назвали «Птичье молоко»? https://e-pochemuchka.ru/ptiche-moloko-ot-drevnih-mifov-k-lyubimomu-lakomstvu/
мтс тв новосибирск
http://epsontario.com/employer/buynbagit8362/
мтс цены
мтс интернет
http://kandan.net/employer/webdschool893
мтс телевидение
мтс цены
http://vts-maritime.com/employer/inetrnet-domashnij-ekb-3/
мтс тарифы на интернет
мтс подключение екатеринбург
http://kandan.net/employer/inetrnet-domashnij-ekb
мтс тарифы на интернет
мтс домашний интернет
https://kennetjobs.com/companies/inetrnet-domashnij-ekb-2/
мтс тв екатеринбург
мтс тв
https://www.vieclam.jp/employer/inetrnet-domashnij-ekb-3/
мтс тарифы екатеринбург
El codigo promocional 1xBet 2025: “1XBUM” brinda a los nuevos usuarios un bono del 100% hasta $130. Ademas, el codigo promocional 1xBet de hoy permite acceder a un atractivo bono de bienvenida en la seccion de casino, que ofrece hasta $2275 USD (o su equivalente en VES) junto con 150 giros gratis. Este codigo debe ser ingresado al momento de registrarse en la plataforma para poder disfrutar del bono de bienvenida, ya sea para apuestas deportivas o para el casino de 1xBet. Los nuevos clientes que se registren utilizando el codigo promocional tendran la oportunidad de beneficiarse de la bonificacion del 100% para sus apuestas deportivas.
Utiliza el codigo de bonificacion de 1xCasino: “1XBUM” para obtener un bono VIP de hasta €1950 mas 150 giros gratis en el casino y un 200% hasta €130 en apuestas deportivas. Introduce nuestro codigo promocional para 1x Casino 2025 en el formulario de registro y reclama bonos exclusivos para el casino y las apuestas deportivas. Bonificacion sin deposito de 1xCasino de $2420. Es necesario registrarse, confirmar tu correo electronico e ingresar el codigo promocional.
1xbet app
мтс интернет екатеринбург
https://dlya-nas.com/employer/inetrnet-domashnij-ekb/
мтс подключение екатеринбург
мтс цены
https://jobsspecialists.com/companies/inetrnet-domashnij-ekb-2/
мтс интернет екатеринбург
мтс тарифы екатеринбург
https://www.ritej.com.tn/employer/inetrnet-domashnij-ekb-3/
мтс телевидение
мегафон телевидение
https://ekb-domasnij-internet-2.ru
мегафон телевидение
мегафон телевидение
https://ekb-domasnij-internet-3.ru
мегафон подключение екатеринбург
мегафон интернет екатеринбург
https://ekb-domasnij-internet.ru
мегафон домашний интернет екатеринбург
сайт билайн краснодар
https://infodomashnij-internet-krasnodar-2.ru
билайн тв краснодар
билайн тарифы краснодар
https://infodomashnij-internet-krasnodar-3.ru
билайн интернет краснодар
сайт билайн краснодар
https://infodomashnij-internet-krasnodar.ru
билайн телевидение краснодар
Проблемы с сантехникой в Минске? Мы осуществляем установку и замену с гарантией надежности. Наши практикующие специалисты готовы выполнить монтаж. Узнайте больше на Монтаж сантехники Минск .
билайн домашний интернет
https://plus-domashnij-internet-krasnodar-2.ru
билайн подключение
провайдер билайн
https://plus-domashnij-internet-krasnodar.ru
билайн телевидение краснодар
билайн подключить краснодар
https://plus-domashnij-internet-krasnodar-3.ru
билайн тарифы краснодар
билайн подключить
https://plus-domashnij-internet-krasnodar-2.ru
билайн тв
билайн подключить краснодар
https://plus-domashnij-internet-krasnodar.ru
билайн интернет краснодар
билайн интернет
https://plus-domashnij-internet-krasnodar-3.ru
билайн тарифы на интернет
билайн подключить
https://plus-domashnij-internet-krasnodar-2.ru
билайн тарифы краснодар
провайдер билайн
https://plus-domashnij-internet-krasnodar.ru
билайн тв
билайн интернет
https://plus-domashnij-internet-krasnodar-3.ru
билайн подключение краснодар
Психолог помогающий искать решения в непростых психологических ситуациях. Психологическая и информационная онлайн-помощь. Получить КОНСУЛЬТАЦИЮ и ПОДДЕРЖКУ профессиональных психологов.
Психологическая и информационная онлайн-помощь. Психолог помогающий искать решения в непростых психологических ситуациях. Психолог оказывает помощь онлайн в чате.
Чат психологической поддержки. Чат психологической поддержки. Чат психологической поддержки.
мегафон екатеринбург
мегафон екатеринбург
провайдер мегафон
Телеграм психолог. Получить КОНСУЛЬТАЦИЮ и ПОДДЕРЖКУ профессиональных психологов. Чат психологической поддержки.
Психолог оказывает помощь онлайн в чате. Получить КОНСУЛЬТАЦИЮ и ПОДДЕРЖКУ профессиональных психологов. Психолог в телеграм.
Чат с психологом в телеге. Психолог в телеграм. Получите консультацию онлайн-психолога в чате прямо сейчас.
мегафон домашний интернет
https://plus-ekb-domasnij-internet-2.ru
мегафон тв екатеринбург
Психологическая и информационная онлайн-помощь. Анонимный чат с психологом телеграм. Психологическая и информационная онлайн-помощь.
Помощь психолога онлайн. Получите консультацию онлайн-психолога в чате прямо сейчас. Психолог помогающий искать решения в непростых психологических ситуациях.
Чат психологической поддержки. Телеграм психолог. Онлайн чат с психологом без регистрации.
Психолог помогающий искать решения в непростых психологических ситуациях. Психолог t me. Психолог оказывает помощь онлайн в чате.
мегафон екатеринбург
https://plus-ekb-domasnij-internet-3.ru
мегафон домашний интернет екатеринбург
В переписке у психолога. Чат с психологом в телеге. В переписке у психолога.
мегафон тарифы екатеринбург
мегафон екатеринбург
мегафон интернет екатеринбург
провайдер мегафон
https://plus-ekb-domasnij-internet-2.ru
мегафон домашний интернет екатеринбург
мегафон подключение
https://plus-ekb-domasnij-internet-3.ru
мегафон екатеринбург
мегафон подключить екатеринбург
провайдер мегафон
провайдер мегафон
мегафон подключение
https://plus-ekb-domasnij-internet-2.ru
мегафон домашний интернет
мегафон подключить
https://plus-ekb-domasnij-internet-3.ru
мегафон телевидение
Получите консультацию онлайн-психолога в чате прямо сейчас. Получить первую онлайн консультацию психолога чате. Помощь психолога онлайн.
Получить онлайн консультацию психолога чате. Получите консультацию онлайн-психолога в чате прямо сейчас. Круглосуточная запись на онлайн-консультацию психолога.
Получите консультацию онлайн-психолога в чате прямо сейчас. Чат с психологом в телеге. Онлайн-консультация психолога.
мегафон домашний интернет
мегафон тарифы екатеринбург
провайдер мегафон
билайн тарифы кемерово
https://job-daddy.com/employer/candelaria/
билайн тв
мтс подключить
https://ckzink.com/profile/brigidaharry57
мтс интернет кемерово
мтс интернет
https://agedcarepharmacist.com.au/employer/carma/
мтс тв краснодар
мегафон тарифы ростов
https://essex.club/employer/leigh/
мегафон домашний интернет
сайт билайн кемерово
https://job-daddy.com/employer/candelaria/
билайн телевидение
ттк тв барнаул
https://neejobs.com/employer/ttk-tarif-llc/
ттк подключить
мтс телевидение кемерово
https://skilling-india.in/employer/paula/
мтс кемерово
мтс интернет
https://lazerjobs.in/employer/carmela/
мтс подключение
сайт ттк ростов
https://philadelphiaflyersclub.com/read-blog/13554_ttk-internet-poisk-i-ustranenie-nepoladok.html
ттк тарифы ростов
мегафон телевидение
https://jobs.kwintech.co.ke/companies/ernie/
мегафон тарифы на интернет
провайдер билайн
http://www.trabahopilipinas.com/employer/freya/
билайн подключить кемерово
Hello!
This post was created with XRumer 23 StrongAI.
Good luck 🙂
билайн цены
http://lesstagiaires.com/employer/lorenzo/
билайн домашний интернет кемерово
мтс домашний интернет кемерово
https://iadgroup.co.uk/employer/nancy/
мтс подключение кемерово
мтс подключить краснодар
https://electroplatingjobs.in/employer/breanna/
мтс краснодар
мтс тв
http://fatims.org/employer/amelie/
мтс цены
мегафон подключить
http://jobsgo.co.za/employer/brandi
мегафон интернет ростов
ттк тарифы на интернет
https://www.bjs-personal.hu/munkaado/ttk-tarif-ltd/
ттк подключение барнаул
мтс краснодар
http://minority2hire.com/employer/graciela/
мтс подключение
ттк подключение
https://sunnyskiesproduce.com/employer/elizabeth/
провайдер ттк
билайн интернет
https://hifrequency.live/community/profile/leonelgann7839/
билайн интернет
сайт мегафон ростов
https://www.indianpharmajobs.in/employer/elliott/
мегафон тарифы на интернет
мтс интернет
http://www.jobteck.co.in/companies/benito/
мтс тв кемерово
мтс телевидение
https://hektips.com/employer/beatriz/
мтс краснодар
мегафон интернет
https://smarthr.hk/Companies/bessie/
мегафон интернет
ттк цены
https://zimtechinfo.com/companies/ttk-tarif-and-co/
ттк домашний интернет барнаул
ттк тарифы на интернет
https://u-hired.com/employer/ttk-tarif-services/
ттк подключить
провайдер ттк
https://gmstaffingsolutions.com/employer/brianne/
ттк подключение ростов
ттк интернет
https://www.jobs-f.com/employer/odessa/
ттк тарифы ростов
билайн тв
https://pittsburghpenguinsclub.com/read-blog/19155_bilajn-domashnij-internet-otzyvy-polzovatelej.html
провайдер билайн
мтс цены
https://jobistan.af/employer/kellie/
мтс интернет кемерово
мтс цены
https://xpressrh.com/employer/arielle/
мтс телевидение
мегафон подключение ростов
https://smarthr.hk/Companies/bessie/
мегафон подключить
ттк тарифы на интернет
https://ready4hr.com/employer/ttk-tarif-and-co/
ттк тв
ттк тв ростов
http://jobsgo.co.za/employer/brianne
ттк подключение ростов
билайн интернет кемерово
https://www.mpowerplacement.com/employer/buck/
билайн тв
провайдер мтс
https://www.ayurjobs.net/employer/horacio/
мтс тарифы кемерово
мтс домашний интернет краснодар
https://www.ritej.com.tn/employer/bret/
мтс подключить краснодар
ттк тв
http://www.mizmiz.de/read-blog/125034_%D0%BA%D0%B0%D0%BA-%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D1%82%D1%8C-%D0%BE%D0%BF%D1%82%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9-%D1%82%D0%B0%D1%80%D0%B8%D1%84-%D1%82%D1%82%D0%BA-%D0%B4%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B5%D0%B3%D0%BE-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B0-%D0%B2-%D0%B1%D0%B0%D1%80%D0%BD%D0%B0%D1%83%D0%BB%D0%B5.html
ттк интернет барнаул
ттк подключение ростов
https://dev-members.writeappreviews.com/employer/brett/
ттк тв ростов
vibracion de motor
Sistemas de equilibrado: fundamental para el desempeño uniforme y eficiente de las equipos.
En el entorno de la tecnología moderna, donde la eficiencia y la estabilidad del sistema son de gran importancia, los equipos de ajuste tienen un tarea vital. Estos equipos dedicados están concebidos para equilibrar y fijar elementos rotativas, ya sea en equipamiento manufacturera, transportes de transporte o incluso en aparatos domésticos.
Para los técnicos en reparación de dispositivos y los técnicos, operar con aparatos de ajuste es esencial para asegurar el rendimiento fluido y confiable de cualquier aparato móvil. Gracias a estas herramientas tecnológicas modernas, es posible disminuir significativamente las sacudidas, el sonido y la presión sobre los sujeciones, aumentando la longevidad de componentes costosos.
Asimismo importante es el papel que desempeñan los aparatos de balanceo en la asistencia al cliente. El ayuda profesional y el conservación regular aplicando estos dispositivos facilitan ofrecer prestaciones de gran excelencia, mejorando la agrado de los compradores.
Para los dueños de proyectos, la contribución en unidades de balanceo y detectores puede ser fundamental para optimizar la productividad y rendimiento de sus aparatos. Esto es sobre todo relevante para los emprendedores que gestionan pequeñas y modestas negocios, donde cada punto cuenta.
Asimismo, los dispositivos de balanceo tienen una vasta uso en el ámbito de la seguridad y el supervisión de estándar. Posibilitan localizar probables fallos, evitando intervenciones onerosas y perjuicios a los sistemas. Además, los datos obtenidos de estos dispositivos pueden utilizarse para maximizar procesos y aumentar la visibilidad en buscadores de consulta.
Las campos de aplicación de los dispositivos de balanceo cubren variadas ramas, desde la manufactura de bicicletas hasta el monitoreo ambiental. No influye si se considera de enormes producciones industriales o pequeños locales hogareños, los aparatos de ajuste son fundamentales para asegurar un funcionamiento productivo y sin presencia de fallos.
análisis de vibraciones
Aparatos de calibración: clave para el operación fluido y eficiente de las equipos.
En el mundo de la tecnología moderna, donde la efectividad y la seguridad del dispositivo son de máxima trascendencia, los aparatos de calibración juegan un tarea fundamental. Estos equipos adaptados están creados para equilibrar y estabilizar piezas móviles, ya sea en maquinaria manufacturera, medios de transporte de transporte o incluso en equipos domésticos.
Para los especialistas en mantenimiento de dispositivos y los profesionales, operar con equipos de ajuste es fundamental para asegurar el rendimiento fluido y seguro de cualquier aparato móvil. Gracias a estas opciones innovadoras innovadoras, es posible minimizar significativamente las vibraciones, el estruendo y la carga sobre los soportes, aumentando la longevidad de componentes costosos.
También relevante es el función que cumplen los aparatos de calibración en la soporte al comprador. El ayuda profesional y el reparación regular usando estos sistemas posibilitan brindar prestaciones de óptima estándar, elevando la agrado de los compradores.
Para los dueños de emprendimientos, la inversión en unidades de ajuste y detectores puede ser importante para aumentar la productividad y productividad de sus dispositivos. Esto es especialmente importante para los emprendedores que administran pequeñas y pequeñas emprendimientos, donde cada elemento es relevante.
También, los equipos de equilibrado tienen una vasta uso en el área de la prevención y el gestión de excelencia. Facilitan encontrar eventuales errores, impidiendo reparaciones onerosas y daños a los aparatos. También, los resultados recopilados de estos sistemas pueden emplearse para maximizar métodos y potenciar la exposición en buscadores de exploración.
Las áreas de implementación de los equipos de calibración incluyen diversas sectores, desde la manufactura de ciclos hasta el supervisión ambiental. No importa si se refiere de enormes manufacturas industriales o modestos establecimientos hogareños, los equipos de ajuste son necesarios para proteger un desempeño productivo y sin riesgo de fallos.
Jante Rimnova
Jante Rimnova
Психолог оказывает помощь онлайн в чате. Помощь психолога онлайн. Получите консультацию онлайн-психолога в чате прямо сейчас.
Чат с психологом в телеге. Чат с психологом в телеге. Получить КОНСУЛЬТАЦИЮ и ПОДДЕРЖКУ профессиональных психологов.
great blog very nice articles I will follow you continuously sohbet odaları
situs togel terpercaya
Info Terbaru Kompetisi Spin Toto Slot 88 & Tebak Angka Togel 4D Terpercaya – TOGELONLINE88
togel 4d
TOGELONLINE88 sajikan update terbaru tentang kompetisi spin Toto Slot 88 dan tebakan angka 4D terunggul. Aplikasi ini menawarkan platform legal dengan keandalan, hasil valid, sekaligus pengalaman bermain yang nyaman dan teratur.
Lebih dari itu, TOGELONLINE88 juga menyediakan puluhan provider game slot dan game tembak ikan yang bisa dimainkan kapanpun dan dimanapun, dengan potensi memenangkan hadiah jackpot maksimal yang luar biasa besar.
Untuk penggemar game togel & slot digital, TOGELONLINE88 menjadi pilihan utama karena menjamin kemudahan, perlindungan, dan keseruan saat bermain. Melalui promo-promo menarik serta platform user-friendly, layanan ini memberikan kenyamanan gaming yang tak terlupakan.
Jadi, tunggu apa lagi? Segera ikuti kompetisi spin Toto Slot 88 dan pasang angka togel 4D terbaik hanya di TOGELONLINE88. Dapatkan kesempatan menang dan nikmati sensasi jackpot maxwin yang menggelegar!
agen togel
Info Menarik Event Spin Toto Slot 88 & Pasang Angka Togel 4D Terpercaya – TOGELONLINE88
TOGELONLINE88 hadir memberikan informasi menarik seputar lomba spin Toto Slot 88 dan pasang angka togel 4D terbaik. Platform ini menyediakan sistem terpercaya yang terpercaya, data akurat, serta pengalaman gaming yang nyaman dan teratur.
Selain itu, TOGELONLINE88 turut menghadirkan banyak penyedia permainan slot dan tembak ikan yang bisa dimainkan 24/7 tanpa batas, dengan kesempatan mendapatkan hadiah jackpot maksimal yang luar biasa besar.
Kepada penggemar permainan togel dan slot online, TOGELONLINE88 merupakan pilihan terbaik dengan menawarkan kenyamanan, perlindungan, dan hiburan saat bermain. Dengan penawaran istimewa beserta sistem akses mudah, layanan ini memberikan pengalaman bermain luar biasa.
Tunggu apalagi? Gabung dalam lomba spin Toto Slot 88 dan tebak angka 4D unggulan hanya di TOGELONLINE88. Dapatkan kesempatan menang dan nikmati sensasi jackpot maxwin luar biasa!
bocor88 login
Workflow automation
Build AI Agents and Integrate with Apps & APIs
AI agents are revolutionizing business automation by creating intelligent systems that think, decide, and act independently. Modern platforms offer unprecedented capabilities for building autonomous AI teams without complex development.
Key Platform Advantages
Unified AI Access
Single subscription provides access to leading models like OpenAI, Claude, Deepseek, and LLaMA—no API keys required for 400+ AI models.
Flexible Development
Visual no-code builders let anyone create AI workflows quickly, with code customization available for advanced needs.
Seamless Integration
Connect any application with AI nodes to build autonomous workers that interact with existing business systems.
Autonomous AI Teams
Modern platforms enable creation of complete AI departments:
– AI CEOs for strategic oversight
– AI Analysts for data insights
– AI Operators for task execution
These teams orchestrate end-to-end processes, handling everything from data analysis to continuous optimization.
Cost-Effective Scaling
Combine multiple LLMs for optimal results while minimizing costs. Direct vendor pricing and unified subscriptions simplify budgeting while scaling from single agents to full departments.
Start today—launch your AI agent team in minutes with just one click.
—
Transform business operations with intelligent AI systems that integrate seamlessly with your applications and APIs.
toto 4d
Selamat datang di dunia taruhan digital! Platform togel terbaik! Zona publik terbaik untuk bermain platform gaming slot dan togel terbaik modern 2025
Tahun 2025 ini, Togelonline88 kembali hadir sebagai zona publik terbaik untuk bermain togel 4D online dan toto slot online dengan banyak kelebihan. Situs ini menyediakan alamat utama dengan reputasi terjaga, menyediakan akses instan kepada seluruh pengguna melakukan bet daring secara aman
Salah satu daya tarik utama situs ini yaitu sistem permainan yang rutin memunculkan petir merah x1000, yang merupakan simbol hadiah fantastis dan jackpot menguntungkan. Hal ini menjadikan situs ini sangat diminati di kalangan penggemar togel dan slot online di Indonesia
Selain itu, Togelonline88 menawarkan sensasi bermain dengan kualitas premium. Dengan tampilan antarmuka yang ramah pengguna dan sistem keamanan terbaru, situs ini memastikan setiap pemain bisa bermain santai tanpa cemas kebocoran informasi atau kecurangan. Keterbukaan angka keluaran result togel dan pembayaran kemenangan juga menjadi nilai tambah yang menjadikan bettor merasa aman dan betah bermain
Dengan berbagai fitur unggulan dan layanan terbaik, platform ini menjadi alternatif utama bettor untuk menemukan platform togel dan slot online terpercaya di tahun 2025. Daftar segera nikmati sensasi bermain di tempat togel online termodern serta paling komplit di situs ini!
togelonline88
Selamat datang di dunia taruhan digital! Situs taruhan online terpercaya! Area bermain resmi situs taruhan slot dan togel 4D unggulan tahun ini
Sepanjang 2025, Togelonline88 kembali hadir sebagai zona publik terbaik bermain taruhan 4D dan slot dengan banyak kelebihan. Tersedia link terverifikasi yang aman dan terpercaya, memudahkan akses bagi para pemain bermain secara digital secara aman
Salah satu daya tarik utama situs ini berupa mekanisme bet yang rutin memunculkan bonus besar x1000, sebagai indikator keberuntungan luar biasa serta jackpot menggiurkan. Keunggulan ini menjadikan situs ini sangat populer oleh para bettor dan bettor tanah air
Selain itu, situs ini memberikan pengalaman gaming dengan kualitas premium. Bermodalkan interface user-friendly dengan enkripsi terdepan, situs ini memastikan semua bettor dapat bermain dengan tenang tanpa cemas kebocoran informasi dan praktik curang. Kejujuran pada hasil draw angka togel serta pencairan hadiah juga menjadi nilai tambah yang menjadikan bettor lebih percaya diri dan nyaman
Dengan berbagai fitur unggulan dan layanan terbaik, platform ini menjadi alternatif utama bettor dalam mencari situs togel serta slot terbaik di tahun 2025. Ayo join sekarang rasakan pengalaman bermain di area bet digital terbaik dan terlengkap hanya di Togelonline88!
situs toto togel 4d
Halo para penggemar togel! Platform togel terbaik! Area bermain resmi link situs toto slot & bet togel 4D online unggulan tahun ini
Sepanjang 2025, Togelonline88 hadir kembali sebagai platform utama melakukan bet online dengan berbagai keunggulan menarik. Menyediakan link terverifikasi dengan reputasi terjaga, menyediakan akses instan bagi para pemain bermain secara digital dengan nyaman dan aman
Fasilitas andalan dari Togelonline88 berupa mekanisme bet yang rutin memunculkan petir merah x1000, yang merupakan simbol kemenangan besar plus untung besar. Keunggulan ini menjadikan platform ini begitu terkenal dari komunitas togel serta pengguna slot online
Tidak hanya itu, situs ini memberikan pengalaman gaming yang modern, transparan, dan menguntungkan. Bermodalkan interface yang ramah pengguna plus proteksi mutakhir, situs ini pastikan seluruh user bisa bermain santai tanpa risiko privasi maupun penipuan. Keterbukaan angka keluaran result togel plus distribusi kemenangan ikut memberi kelebihan yang membuat pemain lebih percaya diri dan nyaman
Berbekal fitur-fitur istimewa dengan service terbaik, Togelonline88 siap menjadi pilihan favorit para player dalam mencari situs togel dan slot online terpercaya di tahun 2025. Daftar segera rasakan pengalaman bermain di zona publik taruhan online tercanggih dan terlengkap di situs ini!
implant dentar zirconiu
Apps integrations
Build AI Agents and Integrate with Apps & APIs
AI agents are revolutionizing business automation by creating intelligent systems that think, decide, and act independently. Modern platforms offer unprecedented capabilities for building autonomous AI teams without complex development.
Key Platform Advantages
Unified AI Access
Single subscription provides access to leading models like OpenAI, Claude, Deepseek, and LLaMA—no API keys required for 400+ AI models.
Flexible Development
Visual no-code builders let anyone create AI workflows quickly, with code customization available for advanced needs.
Seamless Integration
Connect any application with AI nodes to build autonomous workers that interact with existing business systems.
Autonomous AI Teams
Modern platforms enable creation of complete AI departments:
– AI CEOs for strategic oversight
– AI Analysts for data insights
– AI Operators for task execution
These teams orchestrate end-to-end processes, handling everything from data analysis to continuous optimization.
Cost-Effective Scaling
Combine multiple LLMs for optimal results while minimizing costs. Direct vendor pricing and unified subscriptions simplify budgeting while scaling from single agents to full departments.
Start today—launch your AI agent team in minutes with just one click.
—
Transform business operations with intelligent AI systems that integrate seamlessly with your applications and APIs.
supermoney88
supermoney88
API integration
Build AI Agents and Integrate with Apps & APIs
AI agents are revolutionizing business automation by creating intelligent systems that think, decide, and act independently. Modern platforms offer unprecedented capabilities for building autonomous AI teams without complex development.
Key Platform Advantages
Unified AI Access
Single subscription provides access to leading models like OpenAI, Claude, Deepseek, and LLaMA—no API keys required for 400+ AI models.
Flexible Development
Visual no-code builders let anyone create AI workflows quickly, with code customization available for advanced needs.
Seamless Integration
Connect any application with AI nodes to build autonomous workers that interact with existing business systems.
Autonomous AI Teams
Modern platforms enable creation of complete AI departments:
– AI CEOs for strategic oversight
– AI Analysts for data insights
– AI Operators for task execution
These teams orchestrate end-to-end processes, handling everything from data analysis to continuous optimization.
Cost-Effective Scaling
Combine multiple LLMs for optimal results while minimizing costs. Direct vendor pricing and unified subscriptions simplify budgeting while scaling from single agents to full departments.
Start today—launch your AI agent team in minutes with just one click.
—
Transform business operations with intelligent AI systems that integrate seamlessly with your applications and APIs.
SEO Pyramid 10000 Backlinks
Inbound links of your site on forums, blocks, comments.
The 3-step backlinking method
Stage 1 – Standard external links.
Step 2 – Links via 301 redirects from highly reliable sites with PR 9–10, for example –
Step 3 – Listing on SEO analysis platforms –
The key benefit of analyzer sites is that they highlight the Google search engine a website structure, which is crucial!
Note for the third stage – only the main page of the site is added to analyzers, internal pages cannot be included.
I complete all steps step by step, resulting in 10,000–20,000 inbound links from the full process.
This linking tactic is the best approach.
Example of placement on analyzer sites via a .txt document.
how to win pokies nz, casino online uk paypal and australian gambling law, or
free online games win real money no deposit
usa
Here is my site … Goplayslots.Net
AI agents
Build AI Agents and Integrate with Apps & APIs
AI agents are revolutionizing business automation by creating intelligent systems that think, decide, and act independently. Modern platforms offer unprecedented capabilities for building autonomous AI teams without complex development.
Key Platform Advantages
Unified AI Access
Single subscription provides access to leading models like OpenAI, Claude, Deepseek, and LLaMA—no API keys required for 400+ AI models.
Flexible Development
Visual no-code builders let anyone create AI workflows quickly, with code customization available for advanced needs.
Seamless Integration
Connect any application with AI nodes to build autonomous workers that interact with existing business systems.
Autonomous AI Teams
Modern platforms enable creation of complete AI departments:
– AI CEOs for strategic oversight
– AI Analysts for data insights
– AI Operators for task execution
These teams orchestrate end-to-end processes, handling everything from data analysis to continuous optimization.
Cost-Effective Scaling
Combine multiple LLMs for optimal results while minimizing costs. Direct vendor pricing and unified subscriptions simplify budgeting while scaling from single agents to full departments.
Start today—launch your AI agent team in minutes with just one click.
—
Transform business operations with intelligent AI systems that integrate seamlessly with your applications and APIs.
Link Pyramid Backlinks SEO Pyramid Backlink For Google
Backlinks of your site on forums, blocks, threads.
Three-stage backlink strategy
Phase 1 – Basic inbound links.
Step 2 – Backlinks through redirects from top-tier sites with PageRank PR 9–10, for example –
Stage 3 – Listing on SEO analysis platforms –
The key benefit of link analysis platforms is that they display the Google search engine a website structure, which is essential!
Clarification for the third stage – only the homepage of the site is submitted to analyzers, internal pages aren’t accepted.
I complete all three stages sequentially, resulting in 10K–20K backlinks from the full process.
This linking tactic is highly efficient.
Example of placement on analyzer sites via a .txt document.
Harika bir yazı olmuş, teşekkürler. Özellikle Bursa’nın yoğun trafiğinde neyle karşılaşacağımız belli olmuyor. Olası bir durumda elimde kanıt olması için kaliteli bir bursa araç kamerası almayı düşünüyorum. Bu yazı karar vermemde çok yardımcı oldu.
Ehliyetimi yeni aldım ve trafiğe çıkmaya biraz çekiniyorum. Ailem, başıma bir şey gelirse kanıt olması açısından bir bursa araç kamerası almamı tavsiye etti. Yeni başlayanlar için kullanımı kolay bir model öneriniz olur mu?
Backlinks Blogs and Comments, SEO promotion, site top, indexing, links
External links of your site on community platforms, sections, comments.
Backlinks – three steps
Stage 1 – Basic inbound links.
Step 2 – Backlinks through redirects from highly reliable sites with PR 9–10, for example –
Stage 3 – Adding to backlink checkers –
The advantage of link analysis platforms is that they highlight the Google search engine a website structure, which is crucial!
Explanation for Stage 3 – only the main page of the site is submitted to analyzers, internal pages aren’t accepted.
I execute all steps step by step, resulting in 10,000–20,000 inbound links from the full process.
This backlink strategy is most effective.
Demonstration of placement on analyzer sites via a TXT file.
Link Pyramid Backlinks SEO Pyramid Backlink For Google
Quality backlinks to your domain on a wide range of resources.
We use only sources from where there will be no issues from the platform moderators!!!
Generating backlinks in 3 simple stages
Phase 1 – Backlinks to articles (Posting an piece of content on a subject with an anchor and non-anchor link)
Step 2 – Backlinks through redirects of highly reliable sites with domain rating Authority 9-10, e.g.
Step 3 – Posting an example on analyzer sites –
SEO tools provide the sitemap to the Google search engine, and this is crucial.
Explanation for step 3 – only the main page of the site is indexed on the analyzers; subsequent web pages cannot be placed.
I perform these 3 stages in order, in all there will be 10K-30K backlinks from these 3 steps.
This link building approach is the most effective.
I will send the placement on data sources in a document.
Catalog of SEO platforms hundreds of pieces.
Submit a performance report via majestic, semrush , or ahrefs If one of the services has fewer links, I report using the service with the highest number of backlinks because what’s the point of the delay?