
几年工作中数据库的使用必不可少,非关系型数据库以及各种数据仓库占大头;至于关系型数据库(主要就是mysql和oracle)用得不多,涉及到的也就是使用层面的一些DDL,DML操作。
我列了一个SQL 与 NoSQL的对比,
| sql | nosql |
| 采用二维表结构+关系模型来组织数据;这种结构化的数据非常直观,容易理解 | 以KV模型去存储数据,对数据结构要求低;核心逻辑是通过key来取出value |
| 表与表之间存在关联关系,可以做到多表的联合查询 | 难以做到多表查询 |
| 天然支持SQL语句 | 多数不支持SQL |
| 支持事务,ACID,保证数据的一致性 | 通常不支持事务,对一致性要求不那么高,多数提供最终一致性 |
| 读写性能不高(为了维护一致性,数据的二维表结构解析),支持的并发量较低 | 读写性能高(不需要维护一致性及复杂数据解析),支持高并发 |
| 难以存储海量数据 | 支持海量数据 |
| 扩展性较差,难以做到横向拓展 | 多采用分布式架构;拓展性好,容易做到横向拓展 |
我发现相比于关系型数据库,我对于非关系型数据库的底层了解更多,一些特性的底层实现都比较了解;但是mysql的很多功能都是用到哪里看到哪里,很多底层实现对我来说都还是黑盒。于是花了点时间系统的捋了一下mysql的一些底层知识,随手做一个笔记。
概述
DB vs DBMS
DB本质就是一个存储信息的文件系统,管理数据的软件叫做DBMS,例如mysql, postgresql等
截止2022-6常用DBMS的排名:https://db-engines.com/en/ranking
排名的标准如下:
- Number of mentions of the system on websites, measured as number of results in search engines queries. At the moment, we use Google and Bing for this measurement. In order to count only relevant results, we are searching for <system name> together with the term database, e.g. “Oracle” and “database”.
- General interest in the system. For this measurement, we use the frequency of searches in Google Trends.
- Frequency of technical discussions about the system. We use the number of related questions and the number of interested users on the well-known IT-related Q&A sites Stack Overflow and DBA Stack Exchange.
- Number of job offers, in which the system is mentioned. We use the number of offers on the leading job search engines Indeed and Simply Hired.
- Number of profiles in professional networks, in which the system is mentioned. We use the internationally most popular professional network LinkedIn.
- Relevance in social networks. We count the number of Twitter tweets, in which the system is mentioned.
我是没想到tiDB只排到了107。。。。。
关系型数据库定义(RDBMS):
https://db-engines.com/en/article/Relational+DBMS?ref=RDBMS
Relational database management systems (RDBMS) support the relational (=table-oriented) data model. The schema of a table (=relation schema) is defined by the table name and a fixed number of attributes with fixed data types. A record (=entity) corresponds to a row in the table and consists of the values of each attribute. A relation thus consists of a set of uniform records.
The table schemas are generated by normalization in the process of data modeling.
Certain basic operations are defined on the relations:
classical set operations (union, intersection and difference)
Selection (selection of a subset of records according to certain filter criteria for the attribute values)
Projection (selecting a subset of attributes / columns of the table)
Join: special conjunction of multiple tables as a combination of the Cartesian product with selection and projection.
These basic operations, as well as operations for creation, modification and deletion of table schemas, operations for controlling transactions and user management are performed by means of database languages, with SQL being a well established standard for such languages.
Mysql
非常有代表性的关系型数据库,具有开源,性能好,速度快,社区活跃,软件体积小,容易部署等等优点。
分库分表:mysql数据量到达千万级别之后,就要开始考虑分库分表了
关于非关系型数据库
列式数据库的优点:数据查询只用加载需要的列,可以大量的降低系统的IO操作,降低无用数据向内存的加载,查询性能更高。
关系型数据库一些基础知识
数据库范式
基本概念:
- 超键:能唯一标识一个对象的一个/多个属性
- 候选键:不包括冗余信息的超键
- 主键:某一个候选键
- 外键:
- 主属性:候选键中的属性
- 非主属性
第一范式
每个字段要有原子性,不能再拆分
例如一个字段设计为用户信息:姓名+电话+住址。。。等等就是不合规的
第二范式
在第一范式的基础上:
- 每一条记录都有唯一标识(存在主键)
- 非主键字段要依赖整个主键,而不是主键的一部分(应该把部分依赖的字段单独隔离出来组成一张新表)
第三范式
在第二范式的基础上:
所有非主键字段都不依赖其他非主键字段,即非主键字段之间相互独立;
其他范式
一共有6个范式,高级别的范式都是建立在低级别的基础上,通常情况下只需要满足到3rd NF就可以了。
优缺点:
- 优点:消除数据冗余,扩展性更好
- 缺点:查询效率降低,因为范式等级越高,表更细,表数量更多,关联查询就会带来效率问题
其他设计原则
- 数据表数量越少越好
- 数据表中字段个数越少越好
- 避免联合主键,或者联合主键字段越少越好
- 使用外键和主键越多越好:说明表划分得更细
这里的外键是指逻辑上的外键关系,不是指外键约束:不得使用外键与级联,一切外键概念必须在应用层解决。
数据库设计–数据建模:实体–联系模型/E–R model
ER建模(Entity Relationship Modeling),即实体关系建模,是指提炼业务,归纳并设计对应的“实体-关系”模型的过程。
ER建模最终输出的结果为实体关系图(ERD-Entity Relationship Diagram)。
- 对产品经理而言,ERD体现了实体、属性以及实体间的联系,抽象出了业务的核心特征;
- 对开发人员来说,实体关系图显示数据库中的实体(表)以及该数据库中的表之间的关系,奠定了整个系统的框架基础。
关于Entity实体:业务中的对象,涉及属性的设计
关于Relationship关系:业务中对象的关联关系
- 一对一关联
- 一对多关联
- 多对多关联
- 多对对通常需要有第三张联接表(中间表),将两张表以多对多的关系联接起来
- 自我引用
SQL语句分类
- DDL:数据定义语言 关键字有:create(创建),drop(删除) ,truncate(删除表结构,再创一张表),alter(修改)
- DQL:数据查询语言 关键字有:select
- DML:数据操作语言 关键字有:insert(插入),update(更改),delete(删除)
- TCL:事务控制语言 关键字有:begin,savepoint,rollback,commit
- DCL:数据控制语言 关键字有 :grant,revoke,deny
多表查询
多表查询是RDBMS中非常常见的操作,包括:
- 内连接
- 外连接
- 子查询
错误的多表查询方式-笛卡尔积,又叫cross join,是SQL中两表连接的一种方式。 假如A表中的数据为m行,B表中的数据有n行,那么A和B做笛卡尔积,结果为m*n行。 通常我们都要在实际SQL中避免直接使用笛卡尔积,因为它会使“数据爆炸”,尤其是数据量很大的时候。
内连接:
- 隐式内连接:使用where条件消除无用数据
- SELECT * FROM emp t1,dept t2 WHERE t1.`dept_id`=t2.`id`;
- 显式内连接:
- SELECT * FROM emp t1 INNER JOIN dept t2 ON t1.`dept_id`=t2.`id`;
外连接:
- 左连接
- 右连接
- 外连接
子查询
查询中嵌套查询,称嵌套查询为子查询。
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = ‘财务部’ OR NAME = ‘市场部’);
函数
不同的DBMS内部定义的函数是有差别的。
分类:
- Aggregate聚合函数:面向一系列的值,并返回一个单一的值
- Scalar 单行函数:只操作一行数据
MySQL删除表操作(delete、truncate、drop的区别)
- delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除。
- delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚
- 执行的速度上,drop>truncate>delete
数据库对象
数据库对象就是数据库的组成部分,主要的数据库对象包含:
- 触发器(Trigger):在数据库表中属于用户定义的SQL事务命令集合。如果你对一个数据库表执行删除、插入、修改的时候,命令就能够自动去执行。
- 表(Table)
- 约束(Constraint):通过约束来保证数据的完整性(integrity),即数据的正确且可靠。
- 视图(View)
- 存储过程(Stored Procedure)
- 索引(Index):索引是为了给用户提供快速访问数据的途径,时刻监督数据库表的数据,从而参照特定数据库表列建立起来的一种顺序,主要是为了便于用户访问指定数据,避免数据的重复。
- 缺省值(Default)
- 图表(Diagram):图表,是为了编辑表与表之间的关系,可以理解为数据库表之间的一种关系示意图。
- 用户(User)
- 规则(Rule)
- 数据字典:数据字典是对数据库中的数据、库对象、表对象等的元信息的集合。在MySQL中,数据字典信息内容就包括表结构、数据库名或表名、字段的数据类型、视图、索引、表字段信息、存储过程、触发器等内容。MySQL INFORMATION_SCHEMA库提供了对数据局元数据、统计信息、以及有关MySQL server的访问信息(例如:数据库名或表名,字段的数据类型和访问权限等)。该库中保存的信息也可以称为MySQL的数据字典。
- 函数
约束
数据的校验规则,保证数据的完整性(integrity),即数据的正确且可靠。
分类:
- 非空约束(not null)
- 唯一性约束(unique)
- 主键约束(primary key) PK
- 外键约束(foreign key) FK
- 默认值约束 (Default)
- 自增约束(AUTO_INCREMENT)
视图
MySQL 视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图并不实际存在于数据库中。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的。
数据库中只存放了视图的定义,并没有存放视图中的数据,这些数据都存放在定义视图查询所引用的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。因此,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
视图可以从原有的表上选取对用户有用的信息,那些对用户没用,或者用户没有权限了解的信息,都可以直接屏蔽掉,作用类似于筛选。这样做既使应用简单化,也保证了系统的安全。
注意:因为视图时虚拟表,所以更新视图中的数据实际上是更新创建视图时用到的基本表中的数据。
MySQL 存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
注意:从项目管理,版本管理以及可读性,可维护性的角度讲,并不推荐在项目中大量使用存储过程。
- 变量
- 系统变量
- 全局级别
- 会话级别
- 用户变量
- 系统变量
- 流程控制
- 游标
Mysql partition 分区功能
https://www.cnblogs.com/mzhaox/p/11201715.html
水平分区的模式:
- Range(范围) – 这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过年份划分成三个分区,80年代(1980’s)的数据,90年代(1990’s)的数据以及任何在2000年(包括2000年)后的数据。
- Hash(哈希) – 这种模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如DBA可以建立一个对表主键进行分区的表。
- Key(键值) – Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
- List(预定义列表) – 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据。
- Composite(复合模式) – 很神秘吧,哈哈,其实是以上模式的组合使用而已,就不解释了。举例:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
垂直分区(按列分):
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
注意:partition操作会从底层存储文件就真的将数据进行分区,例如网上一个例子,创建no_part_tab和part_tab两张表,后者分区,灌入同样的数据,它们的底层存储文件为:
2008-05-24 09:23 8,608 no_part_tab.frm
2008-05-24 09:24 255,999,996 no_part_tab.MYD
2008-05-24 09:24 81,611,776 no_part_tab.MYI
2008-05-24 09:25 0 part_tab#P#p0.MYD
2008-05-24 09:26 1,024 part_tab#P#p0.MYI
2008-05-24 09:26 25,550,656 part_tab#P#p1.MYD
2008-05-24 09:26 8,148,992 part_tab#P#p1.MYI
2008-05-24 09:26 25,620,192 part_tab#P#p10.MYD
2008-05-24 09:26 8,170,496 part_tab#P#p10.MYI
2008-05-24 09:25 0 part_tab#P#p11.MYD
2008-05-24 09:26 1,024 part_tab#P#p11.MYI
2008-05-24 09:26 25,656,512 part_tab#P#p2.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p2.MYI
2008-05-24 09:26 25,586,880 part_tab#P#p3.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p3.MYI
2008-05-24 09:26 25,585,696 part_tab#P#p4.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p4.MYI
2008-05-24 09:26 25,585,216 part_tab#P#p5.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p5.MYI
2008-05-24 09:26 25,655,740 part_tab#P#p6.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p6.MYI
2008-05-24 09:26 25,586,528 part_tab#P#p7.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p7.MYI
2008-05-24 09:26 25,586,752 part_tab#P#p8.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p8.MYI
2008-05-24 09:26 25,585,824 part_tab#P#p9.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p9.MYI
2008-05-24 09:25 8,608 part_tab.frm
2008-05-24 09:25 68 part_tab.parMysql 窗口函数功能
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数。 什么叫窗口? 窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。 对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数的区别:聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条;聚合函数也可以用于窗口函数中
窗口函数是很多DBMS支持的特性:
Mysql 派生表与临时表
派生表:
派生表是从SELECT语句返回的虚拟表。派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为它不需要创建临时表的步骤。
与子查询不同,派生表必须具有别名,以便稍后在查询中引用其名称。
派生表是从SELECT语句返回的虚拟表。派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为它不需要创建临时表的步骤。
SELECT
column_list
FROM
(SELECT
column_list
FROM
table_1) derived_table_name;
WHERE derived_table_name.c1 > 0;临时表:
在MySQL中,临时表是一种特殊类型的表,它允许您存储一个临时结果集,可以在单个会话中多次重用。
要创建临时表,只需要将TEMPORARY关键字添加到CREATE TABLE语句的中间。例如,以下语句创建一个临时表,按照收入存储前10名客户:
CREATE TEMPORARY TABLE top10customers
SELECT p.customerNumber,
c.customerName,
FORMAT(SUM(p.amount),2) total
FROM payments p
INNER JOIN customers c ON c.customerNumber = p.customerNumber
GROUP BY p.customerNumber
ORDER BY total DESC
LIMIT 10;现在,可以从top10customers临时表中查询数据,例如:SELECT * FROM top10customers;
Mysql 公用表表达式(common table expressions)
https://blog.csdn.net/qq_45912025/article/details/125182001
对比子查询的优点:
公用表表达式的作用是可以替代子查询,而且可以被多次引用。递归公用表表达式对查询有一个共同根节点的树形结构数据非常高效,可以轻松搞定其他查询方式难以处理的查询。
mysql对Nosql的支持
MySQL 从 5.7 版本开始提供 NoSQL 存储功能,在 8.0 版本中这部分功能也得到了更大的改进。该项功能消除了对独立的 NoSQL 文档数据库的需求,而 MySQL 文档存储也为 schema-less 模式的 JSON 文档提供了多文档事务支持和完整的 ACID 合规性。
Mysql架构
架构
处理流程:
- Step1:处理连接
- Step2:解析优化查询语句
- Step3:交给存储引擎执行(查询文件系统)
- Step4:响应
- 解析器:对sql进行语法解析,生成语法树
- 优化器:对sql进行优化,例如判断使用哪些索引,表连接顺序等等。。。最终生成执行计划
可以将mysql的架构分为3层:
- 连接层
- tcp连接(TCP连接池,复用TCP长连接)
- 鉴权
- 线程池
- 服务层
- SQL Interface
- Cache & buffer(8.0中已经去掉这个模块,因为命中率太低,还要费力维护更新)
- Parser
- Optimizer
- 执行器
- 引擎层
- 负责数据的存储和提取
执行流程
https://cloud.tencent.com/developer/article/1882003
解析器
- 词法分析
- 语法分析
- you have an error in your SQL syntax
- 如果没问题会生成一个语法树
优化器
使用什么索引,简化表达式,join顺序 —》 获得一个最优的执行计划
优化器的思路:
- 物理查询优化
- 通过索引和表连接进行优化
- 例如表连接效率高于子查询:执行子查询时,MYSQL需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响,这里多了一个创建和销毁临时表的过程。可以使用连接查询(JOIN)代替子查询,连接查询不需要建立临时表,因此其速度比子查询快。
- 逻辑查询优化
- 换一种计算方式
- 对语句用更高效的方式重写
执行器
按照执行计划调用底层的存储引擎;
mysql底层存储引擎
MySQL 数据目录的物理结构和作用
配置文件:
Windows 和 Linux 下的 MySQL 配置文件的名字和存放位置都是不同的,WIndows 下 MySQL 配置文件是 `my.ini` 存放在 MySQL 安装目录的根目录下;Linux 下 MySQL 配置文件是 `my.cnf` 存放在 `/etc/my.cnf`、`/etc/mysql/my.cnf`
mysql自带数据库:
- mysql:账户,权限,存储过程,事件等信息
- Information_schema: 数据库的的元数据
- performace_shcema:存储服务器运行过程中的状态信息,能够用来监控各类性能指标
- sys:sys这个数据库主要是通过视图的形式把information_schema和performance_schema结合起来,让程序员可以更方便的了解MySQL服务器的一些性能信息。
http://c.biancheng.net/view/7911.html
- db.opt:
- 用来保存数据库的配置信息,比如该库的默认字符集编码和字符集排序规则。如果你创建数据库时指定了字符集和排序规则,后续创建的表没有指定字符集和排序规则,那么该表将采用 db.opt 文件中指定的属性。
- 高版本这个文件内容合并到数据文件中了
- .frm文件:
- 在 MySQL 中建立任何一张数据表,其对应的数据库目录下都会有该表的 .frm 文件。.frm文件用来保存每个数据表的元数据(meta)和表结构等信息。数据库崩溃时,可以用 .frm 文件恢复表结构。
- .frm 文件跟存储引擎无关,任何存储引擎的数据表都有 .frm 文件,命名方式为表名.frm,如 users.frm。
- MySQL 8.0 版本开始,frm 文件被取消,MySQL 把文件中的数据都写到了系统表空间。通过利用 InnoDB 存储引擎来实现表 DDL 语句操作的原子性(在之前版本中是无法实现表 DDL 语句操作的原子性的,如 TRUNCATE 无法回滚)。
- .MYD和.MYI
- .MYD 理解为My Data,用于存放 MyISAM 表的数据。
- .MYI 理解为My Index,主要存放 MyISAM 表的索引及相关信息。
- .ibd:独立表空间
- 对于 InnoDB 存储引擎的数据表,一个表对应两个文件,一个是 *.frm,存储表结构信息;一个是*.ibd,存储表中数据。
- .ibd和.ibdata:.ibd 和 .ibdata 都是专属于 InnoDB 存储引擎的数据库文件。当采用共享表空间时,所有 InnoDB 表的数据均存放在 .ibdata 中。所以当表越来越多时,这个文件会变得很大。相对应的 .ibd 就是采用独享表空间时 InnoDB 表的数据文件。
- ibdata系统表空间,位于数据库文件上层一个共享的文件,用于早期mysql存储表数据
- 视图存储:
- 是一个虚拟的表,所以只有一个frm文件,没有ibd文件
注意:
- innodb中,数据和索引聚合存储
- myisam中,数据和索引分开存储
存储引擎
直接负责数据的提取和写入
| InnoDB (高版本默认使用) | MyISAM |
| 支持外键(但是不推荐使用外键,效率问题) | 不支持 |
| 支持事务,commit & rollback | 不支持 |
| 除了insert和select操作之外,还有频繁的update,delete,那么应该使用InnoDB,效率更高 | 只有频繁的insert和select操作时,效率更高,访问速度更快,适用只读业务或者以读为主的业务 |
| 对性能进行了优化,擅长处理数据量大的表,并发量大 | 擅长处理数据量较小的表,不支持高并发 |
| 支持行锁 | 支持表锁(所以并发性不好) |
| 崩溃可以安全恢复 | 崩溃不可以进行安全恢复 |
| 索引与数据共同存储 | 索引和数据分别存储 |
InnoDB与MyISAM最大的区别就是:对事务,和行锁的支持
InnoDB的索引实现
加快搜索速度,如果不借助索引,所有的查询都需要做全表的扫描,从而造成大量的磁盘IO次数,查询效率非常低。
InnoDB采用B+Tree:
优点:
- 降低磁盘IO次数
- 通过创建“唯一索引”,可以保证数据的唯一性
- Gourpby 和orderby 可以利用索引降低查询时间
- 等等
缺点:
- 维护索引需要时间,降低了更新/写入/删除的时间
- 占用额外的磁盘空间
当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14″这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
聚簇索引优势
我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
- 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引使用主键作为”指针” 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个”指针”。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
页
页是mysql中磁盘和内存交换的基本单位,也是mysql管理存储空间的基本单位。(磁盘IO的基本单位)
同一个数据库实例的所有表空间都有相同的页大小;默认情况下,表空间中的页大小都为 16KB,当然也可以通过改变 innodb_page_size 选项对默认大小进行修改,需要注意的是不同的页大小最终也会导致区大小的不同。
一次最少从磁盘读取16KB内容到内存中,一次最少把内存中16KB内容刷新到磁盘中,当然了单页读取代价也是蛮高的,一般都会进行预读
系统的一个磁盘块的存储空间往往没有这么大,所以InnoDB每次申请磁盘空间时都会是多个地址连续磁盘块来达到页的大小16KB。在查询数据时一个页中的每条数据都能定位数据记录的位置,这会减少磁盘 I/O 的次数,提高查询效率。InnoDB存储引擎在设计时是将根节点常驻内存的,力求达到树的深度不超过 3,也就是说I/O不超过3次。
页结构:
(0,1,2,3,是record type,1是目录,0是数据)
同样可以将页分为目录页和数据页
- 上图对应的就是ibd文件;
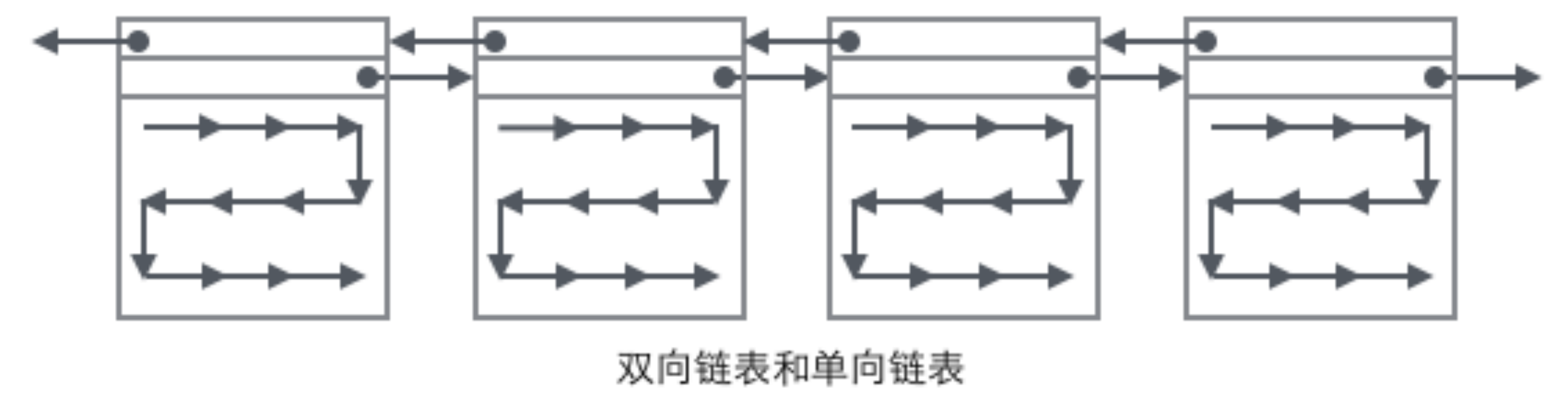
- 页内是按照主键递增的单向链表
- 页间是双向链表
- 叶子结点是数据页,非叶子节点是目录页
- 插入一个主键数据可能会引发数据结构调整(页分裂),拖慢速度,最好以一个自增的ID作为主键,不建议用MD5,UUID,hash之类作为主键
- 更新主键代价大,一般数据库都不允许
- 二级索引查找需要两次索引查找
理解InnoDB的实现不得不提Page结构,Page是整个InnoDB存储的最基本构件,也是InnoDB磁盘管理的最小单位,与数据库相关的所有内容都存储在这种Page结构里。Page分为几种类型,常见的页类型有数据页(B-tree Node)Undo页(Undo Log Page)系统页(System Page) 事务数据页(Transaction System Page)等。单个Page的大小是16K(编译宏UNIV_PAGE_SIZE控制),每个Page使用一个32位的int值来唯一标识,这也正好对应InnoDB最大64TB的存储容量(16Kib * 2^32 = 64Tib)。一个Page的基本结构如下图所示:
我们重点关注和数据组织结构相关的字段:Page的头部保存了两个指针,分别指向前一个Page和后一个Page,头部还有Page的类型信息和用来唯一标识Page的编号。根据这两个指针我们很容易想象出Page链接起来就是一个双向链表的结构。
再看看Page的主体内容,我们主要关注行数据和索引的存储,他们都位于Page的User Records部分,User Records占据Page的大部分空间,User Records由一条一条的Record组成,每条记录代表索引树上的一个节点(非叶子节点和叶子节点)。在一个Page内部,单链表的头尾由固定内容的两条记录来表示,字符串形式的”Infimum”代表开头,”Supremum”代表结尾。这两个用来代表开头结尾的Record存储在System Records的段里,这个System Records和User Records是两个平行的段。InnoDB存在4种不同的Record,它们分别是1主键索引树非叶节点 2主键索引树叶子节点 3辅助键索引树非叶节点 4辅助键索引树叶子节点。这4种节点的Record格式有一些差异,但是它们都存储着Next指针指向下一个Record。后续我们会详细介绍这4种节点,现在只需要把Record当成一个存储了数据同时含有Next指针的单链表节点即可。
联合索引
基于多个字段建立的索引
深入探讨文件与页的关系
TBD:如何在文件中存储页以及页之间的关系
行格式
在BufferPool中,是按照页的形式来存放的。但是数据在表中是一行行的存储的,那么这些数据又是怎样的格式?
就是页面中的一条行记录的格式
有的行格式设计的不紧凑,同样一条记录会占用更多的磁盘空间,意味着一个页里包含的记录就少了,进而会影响DML操作的性能,查询可能需要更多的磁盘IO。有的行格式还会对数据做压缩处理,磁盘IO的效率高了,但是会消耗更多的CPU资源。所以,行格式的选择对数据读写的效率是有影响的,具体如何选择,需要根据场景而定。MySQL5.7版本,默认使用DYNAMIC行格式。
记录在磁盘上的存放方式被称为行格式,InnoDB存储引擎中有4种不同类型的行格式,Compact、Redundant、Dynamic和Compressed。
表空间/段/区/页/行
区(Extent)是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配64个连续的页。因为在InnoDB中页的大小为16KB,所以一个区的大小是64*16KB=1MB。
段(Segment)由一个或者多个区组成,区在文件系统中是一个连续分配的空间(在InnoDB中是连续的64个页),在段中不要求区与区是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段的形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段吗,创建一个索引时会创建一个索引段。
表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间可以有多个或者一个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
索引的分类
- 普通索引、
- 唯一索引、
- 主键索引、
- 组合索引、
- 全文索引
https://www.php.cn/mysql-tutorials-418140.html
mysql事务特性
MySQL事务机制的核心是两个日志文件:
- redo log(重做日志)
- undo log(回滚日志)
ACID
- Atomicity:
- 事务不可分割,不会出现执行到中间被中断的状态
- Consistency:
- 从合法状态向合法状态的转换,不会以错误的中间状态结束;
- 区分分布式系统的一致性
- Isolation:
- 事务互相之间没有干扰
- 存在多种隔离级别
- Duribility
- 数据库一旦被提交,改动就是永久性的,服务器故障不应该影响数据
- 持久性通过事务日志来保证,包括重做日志和回滚日志
事务要么commit,要么rollback;
显式事务&隐式事务
事务主要针对DDL操作,某些数据库系统(例如 MySQL)不支持在事务中运行 DDL,因此别无选择,只能将三个操作(ALTER、ALTER 和然后 UPDATE)作为三个不同的操作运行:如果其中任何一个失败,则无法恢复并回到初始状态。例如,在一个事务中发出了两个 DDL 语句,然后我们回滚了该事务。 MySQL 在任何时候都没有输出任何错误,让我们认为它没有改变我们的表。然而,当检查数据库的模式时,我们可以看到没有任何东西被回滚。 MySQL 不仅不支持事务性 DDL,而且它也没有明确表明自己没有 rollback!
- 显式
- 以start transaction 或者 begin开始
- 以rollback / commit结束
- 可以在事务中设置savepoint,保存点,rollback可以回滚到指定savepoint,然后继续执行其他操作(rollback savepoint不是结束)
- 隐式
- Autocommit = on;对于数据库默认就是on
- 此时所有的DML操作都是独立的事务
- 关闭autocommit,那么执行操作如果不手动commit,那么其他客户端是看不到的
注意:有一些操作会隐式的提交前面的数据
事务分类
- 扁平事务( Flat Transactions)
- 带有保存点的扁平事务(Flat Transactions with Savepoints)
- 链事务(Chained Transactions)
- 嵌套事务(Nested Transactions)
- 分布式事务(Distributed Transactions)
https://blog.csdn.net/c1776167012/article/details/121257852
隔离级别
事务的隔离性是由锁机制来实现的,而事务的ACD是由redo/undo日志来保证的。
mysql数据库事务的隔离级别有4个,而默认的事务处理级别就是【REPEATABLE-READ】,也就是可重复读。
脏写:最基本的保障
- 读未提交
- 没有commit,也可以被别人读到
- 不加锁
- -》存在脏读问题
- 读已提交
- Commit之后,就能被别人读到
- 没有引入写锁
- -》不可重复读问题
- 可重复读
- 一个方案是引入行级别的的写锁
- 但是注意,对行数据的写入操作依然可以commit,并没有阻塞或者失败,但是这个commit的结果并没有呈现在别的事务之中????这个底层究竟是怎么实现的?
- -》幻读问题:
- 串行化
- 引入表级别/或者行级别(视不同的情况而定)的写锁
- 数据应该不能插入进去,会让请求失败,或者阻塞在那里
如何确定自己数据库表的隔离级别?
- 隔离级别越高,并发行越差
- 隔离级别越低,数据一致性越差
- 根据自己的业务模型,看脏读,不可重复读,幻读是否会给我们的业务带来影响,如果会,则设定更高的的隔离级别,如果不会,则可以设定更低级别的隔离级别。
Mysql 设置事务隔离级别,是针对不同的事务之间的,可以设定以下两个范围:
- global级别:
- session级别:
Mysql 锁机制总结
https://zhuanlan.z hihu.com/p/29150809
锁是计算机协调多个进程/线程并发访问某一个资源的机制。数据库中,为了保证数据一致性,同样需要对并发操作进行控制。它也是隔离级别的实现基础。
同时,锁冲突也是影响数据库并发性能的一个重要因素,因此要合理的设计锁的粒度
并发事务情况分类
- 读-读:
- 没有风险
- 写-写:
- 可能会出现脏写问题,即并发写,一个commit,一个rollback,导致commit的结果被回滚
- 必须通过锁来实现排队执行
- 锁是内存中的一个数据结构,与某条记录相关联
- 读-写:
- 可能出现脏读,不可重复读,幻读
读写并发问题的解决方案
方案一:读用MVCC,写操作加锁
核心是读借助readview(类似一个快照): 查询语句会从readview里面读取,readview生成之前的未提交的事务,或者之后提交的事务是查询不到的
- 脏读如何解决:read committed级别下,readview生成之前的未提交的事务读不到
- 不可重复读如何解决:repeatable read级别下,readview生成之后提交的事务读不到
- 幻读如何解决:mysq lrepeatable read级别下,readview生成之后提交的事务读不到(不需要到serializable级别)
方案二:读,写都采用加锁的方式
成本更高,读锁与写锁协同工作;
脏读和不可重复读可以在记录级别加锁,幻读麻烦一点,可能需要别的级别的锁进行控制
共享锁与排他锁
共享锁(S锁,shared lock)又称为读锁:由非更新(读取)操作创建的锁。其他用户可以并发读取数据,但任何事务都不能获取数据上的排它锁,直到已释放所有共享锁。,若事务T对数据对象A加上S锁,则事务T只能读A, 不能修改A;其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁(X锁,exclusive lock),又称为写锁、独占锁,是一种基本的锁类型。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
功能:读–读不阻塞,读写,写写会阻塞
对于InnoDB来说,读/写锁都可以细分为表级别和行级别;
Mysql高版本中还支持给读操作加写锁:
SELECT … FOR UPDATE;
Mysql里当一个操作需要获取某个锁,但是获取不到时,会发生阻塞现象;超时之后会失败退出;如果加了nowait关键字,则直接失败;如果加了skip locked,则会跳过被锁定的数据。
Insert操作通过隐式锁来保护这条新插入的记录在提交前不被访问
不同粒度:表级锁,页级锁,行锁
粒度越低 -》 并发度越好,但是性能开销越大
表级锁
表级别读写锁:
Innodb,myisam都提供提供的表级别的S和X锁,不过一般不会被用到;某些DDL操作,例如alter table, drop table等可能会触发表级锁
myisam在s elect语句前,会给所有的表加读锁,增删改操作之前,会给涉及的表加写锁;innodb不会加表级别的读锁和写锁
表级别的意向锁intention lock:
协调行锁和表锁,支持多粒度(表/行)锁共存;不与行锁冲突的表锁
- 意向共享锁
- 事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁
- 事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
- 例如,我们给某一行加上排他锁,那么数据库给表加上意向排他锁;如果再有人想获取表级别的排他锁,只需要区检查以下意向排他锁就ok了
IX,IS是表级锁,但是不与行级别的X,S锁冲突,只会与表级别的X,S冲突;
表级别的自增锁
对于多个事务对auto_increment操作产生的冲突的解决;当我们向一个有auto increment关键字的主键插入值时,每条语句都要对这个表锁进行竞争。
不过高版本已经不用这个锁了,使用另外的机制保证唯一与递增性;
元数据锁MDL
当一个表做增删改查时,加MDL读锁;当对表结构做修改时,加MDL写锁
行级锁
MyiSam不支持行级锁,只有innodb支持
粒度小,锁冲突发生概率低,并发度高;频繁加锁有开销,可能出现死锁问题;
记录锁(record locks)
同样分为S/X型,就是针对某一条记录加锁
间隙锁Gap Locks
前面提到我们解决幻读有两个解决方式,一种是mvcc,另一种就是间隙锁;解决的问题是,如何给不存在的记录加锁;
例如记录的主键分布为:1,3,6,8,那么给记录6加gap lock,就会阻塞给3到6之间插入记录的操作
如何获得间隙锁:当你尝试去获取一条不存在的记录的锁时,就会获得间隙锁,间隙锁的s/x效果是一样的,没有区别,并且不限制加锁次数
效果:可能会阻塞某一些insert操作
间隙锁触发死锁:两个事务都锁住同一个区间,并且执行insert操作,就会导致死锁,这时候数据库会报deadlock的错误,并且终止回滚某一个事务。
临键锁(next key locks)
记录锁+间隙锁(闭区间,包括边界)
如何获得?Select * from xx where id > 1 and id <=5 ->就获得了一个(1,5]的临键锁。
插入意向锁
页级锁
在页级别的粒度上加锁;一个页会包含多条记录,开销,性能都介于行锁,表锁之间;
什么时候会触发页锁:行锁的数量超过了某个阈值,就会进行锁升级,用更大粒度的页锁来代替行锁;页锁数量到一定规模,也会进行升级,升级为表锁。
乐观锁 & 悲观锁
悲观:通过锁机制,主动保证数据一致性;主动上锁,阻塞其他线程,使用完后开锁
悲观锁例子:
网上商城为了防止超卖,需要通过事务来保证“查询,生成订单,减库存”等一系列操作的事务性,不然就会出现只有一定数量的商品,却卖掉了超过这个数量商品的情况。
缺点是,长事务可能会带来非常大的性能开销,影响吞吐等等;
乐观:认为冲突是小概率事件,不对数据上锁,通过程序来保证数据的一致性
乐观锁实现:版本号机制或者CAS机制
版本号机制:
给版本加一个version,一个事务 读的时候拿到某个version,在写时带着这个version去,如果version小于当前实际version,那么说明就已经有其他事务对version修改过了,这个操作就会失败。
例子

cas机制:
在java concurrent包中很多并发行都是通过CAS机制来实现的
https://zhuanlan.zhihu.com/p/101430930
隐式锁 & 显式锁
和java里面的不同,Java中隐式锁:synchronized;显式锁:lock
显式锁:
隐式锁:
前面讲,在insert的时候,如果间隙加了gap锁,那么insert操作会阻塞,并且给间隙加上插入意向锁;除此之外,是不需要给insert操作加锁的;可是如果在刚刚插入之后(事务没有结束),就有另外的事务要读/更新这条记录,怎么办?
一个事务在对新插入的记录可以不显示的加锁(生成锁结构),但是由于事务id的存在,相当于加了一个隐式锁(记录的事务id和当前事务相同),别的事务在尝试加S/X锁时,才会给之前的事务创建一个锁,这时候才从隐式锁转换成显式锁
在查看表的锁列表时,隐式锁是看不到的;
全局锁
需要使得数据库处于只读状态,就可以加数据库级别的锁(不可以DDL,DML等 操作);应用场景:数据库逻辑备份。
死锁
处理方式:
- 等待事务超时,回滚;默认超时时间50s,可以设置更小,但是容易误伤
- 死锁检测机制:mysql里面会检测出死锁,然后中断并回滚某个事务;默认是打开的

mysql日志文件
redo日志
- 重做日志,恢复相关页操作,保证事务的持久性;
- 事务的持久性针对:已经提交的事务
- 记录的是物理级别的页修改操作,例如页号,偏移量,写入xx数据,保证数据的可靠性。
- 应用场景:我们的修改操作,修改的是内存中加载的页文件,它会按照固定频率刷到磁盘上,但是一旦宕机,内存中的修改就会丢失
- 重启服务,会首先加载redo log把丢失的数据刷盘
- 这种思想在分布式系统里面叫做WAL:Write-Ahead-Logging
- 日志顺序追加,效率非常高,
- Redo log也有内存buffer(redo log buffer),然后写入磁盘其实也是先写到page cache中,再fsync到磁盘的过程(redo log file),这个刷盘策略也是我们非常关注的
- 策略0:系统默认1s 刷盘一次,效率最高
- 策略1:每次事务提交,都会把log buffer中的日志fsync到log file中
- 策略2: 操作系统自己决定什么时候从page cache 刷到磁盘,效率居中
- redo log实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志。
undo日志
- 更新数据的前置操作就是写入undo log
- 回滚日志,回滚到某个特定版本,用来保证事务的原子性,一致性
- 记录逻辑操作的日志,需要执行一条与至相反的操作
- 不是redo日志的顺序追加格式了,每一个事务都有对应的回滚段来存储信息
- 应用场景:事务执行到一半发生服务器故障或者用户手动输入rollback等
- 事务在commit之后,undo log还会保留一段时间;这是因为undo日志还有一个非常重要的功能:事务提交之后,其他事务可以通过undo log来得到之前的版本,这是否就是之前的‘可重复读’遇到问题的答案??是!MVCC
- Undo 日志不像redo日志那样有严格落盘的限制,其实理解成内存里记录一个事务执行前的状态的数据结构更合适
分类:
- Insert undo log:insert的数据具有隔离性,只对事务本身可见,所以在事务提交后可以直接清除undo log
- Update undo log:delete/update操作,例如可重复读中的问题,undo log需要提供MVCC机制,所以不能立刻删除,需要等待一段时间;
binlog日志
包含了所有数据库执行的DDL和DML等数据库更新语句
应用
在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复。
- 主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。
- 数据恢复:通过使用mysqlbinlog工具来恢复数据。
So now let me start with what is happening on the master. For replication to work, first of all master needs to be writing replication events to a special log called binary log. This is usually very lightweight activity (assuming events are not synchronized to disk), because writes are buffered and because they are sequential. The binary log file stores data that replication slave will be reading later.
Whenever a replication slave connects to a master, master creates a new thread for the connection (similar to one that’s used for just about any other server client) and then it does whatever the client – replication slave in this case – asks. Most of that is going to be (a) feeding replication slave with events from the binary log and (b) notifying slave about newly written events to its binary log.
Slaves that are up to date will mostly be reading events that are still cached in OS cache on the master, so there is not going to be any physical disk reads on the master in order to feed binary log events to slave(s). However, when you connect a replication slave that is few hours or even days behind, it will initially start reading binary logs that were written hours or days ago – master may no longer have these cached, so disk reads will occur. If master does not have free IO resources, you may feel a bump at that point.
- binlog是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
binlog刷盘时机
- 对于InnoDB存储引擎而言,只有在事务提交时才会记录biglog,此时记录还在内存中,那么biglog是什么时候刷到磁盘中的呢?mysql通过sync_binlog参数控制biglog的刷盘时机,取值范围是0-N:
- 0:不去强制要求,由系统自行判断何时写入磁盘;
- 1:每次commit的时候都要将binlog写入磁盘;
- N:每N个事务,才会将binlog写入磁盘。
- 从上面可以看出,sync_binlog最安全的是设置是1,这也是MySQL 5.7.7之后版本的默认值。但是设置一个大一些的值可以提升数据库性能,因此实际情况下也可以将值适当调大,牺牲一定的一致性来获取更好的性能。
binlog日志有三种格式
分别为
- STATEMENT: 是什么SQL语句,此时如果使用系统变量,会造成主从执行不同
- ROW:具体的修改是什么,使用系统变量,主从也会一致
- MIXED:结合statement和row,如果有函数,则用row,否则用statement
过期
MySQL expire_logs_days 参数用于控制Binlog文件的保存时间,当Binlog文件存在的时间超过该参数设置的阈值时,Binlog文件就会被自动清除,该参数的时间单位是天,设置为0,表示Binlog文件永不过期,即不自动清除Binlog文件。在MySQL 8.0 版本,该参数被废弃,使用新的参数binlog_expire_logs_seconds代替,新参数的时间粒度是秒,能够更加灵活的控制Binlog文件过期时间。
如果过期清理后,那么没有binlog如何做同步?以及数据恢复??
通常是先以某个时间点做全量快照恢复,再做binlog的指定范围的恢复。
查看
- 通过 mysqlbinlog命令进行二进制文件的查看
- show binlog events
数据恢复
- 同样使用mysqlbinlog命令
- 通常需要定位binlog里面恢复的position范围或者start/stop 的时间
全量备份(快照)
通常使用Mysqldump
两节点提交
如果出现redo写成功,但是写binlog失败
就会出现以下情况
为了防止这种情况产生(redo log 和bin log的不一致),于是使用两阶段提交:
Redo log与binlog区别
一个事务只有提交时才会写入到bin log中;一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入; 但是执行过程中会不断向redo log中写入;
- Redo log侧重于引擎级别的崩溃恢复;binlog侧重数据的同步
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- binlog 会记录表所有更改操作,包括更新删除数据,更改表结构等等,主要用于人工恢复数据,而 redo log 对于我们是不可见的,它是 InnoDB 用于保证 crash-safe 能力的,也就是在事务提交后MySQL崩溃的话,可以保证事务的持久性,即事务提交后其更改是永久性的。==一句话概括:binlog 是用作人工恢复数据,redo log 是 MySQL 自己使用,用于保证在数据库崩溃时的事务持久性。==
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
MVCC特性
https://zhuanlan.zhihu.com/p/66791480
为什么需要MVCC呢?数据库通常使用锁来实现隔离性。最原生的锁,锁住一个资源后会禁止其他任何线程访问同一个资源。但是很多应用的一个特点都是读多写少的场景,很多数据的读取次数远大于修改的次数,而读取数据间互相排斥显得不是很必要。所以就使用了一种读写锁的方法,读锁和读锁之间不互斥,而写锁和写锁、读锁都互斥。这样就很大提升了系统的并发能力。之后人们发现并发读还是不够,又提出了能不能让读写之间也不冲突的方法,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据。当然快照是一种概念模型,不同的数据库可能用不同的方式来实现这种功能。
InnoDB中通过undo log实现了数据的多版本,而并发控制通过锁来实现。
刷脏
脏页:此时内存中的数据和磁盘中的数据是不一致的,不一致的这个数据页就被称为“脏页”。
刷脏:既然磁盘中的数据和内存中的数据有不一致的,那肯定就涉及到将内存中的数据同步到磁盘中,那这个过程就被称为“刷脏”。
刷脏页一般发生在commit之后,redo和binlog提交之后。innodb可以根据脏页在bufferpool中的水位强制刷脏页。Adaptive Flushing根据数据库负载情况调整刷每秒应该刷多少脏页。
其他日志
- 慢查询日志
- 通用查询日志:所有跟请求,处理,响应相关的通用信息
- 错误日志
- 中继日志:
- 数据定义语句日志
主从架构与数据同步
功能
主从架构(集群)可以做到:
- 读写分离,提高数据库处理并发的能力
- 数据备份
- 高可用性(主从切换)
架构
中继日志:只在从服务器上存在,从主服务器读到的二进制文件存储在本地;从服务器数据的同步是通过读取中继日志;
主从复制原理
存在问题–延迟造成一致性问题
主节点数据落盘到同步到从节点,可能会经历一段延迟,这段延迟会造成读写的不一致性;
- 读写都在主库,则不存在一致性问题,从库只是备份
- 弱一致性-异步复制:主commit之后,写完binlog,就给client返回成功,不管从库是否同步完成
- 半同步复制:保证至少一个从库同步完成,再返回客户端,如果把同步数量设定为从库数量,那么就变成完全同步的复制,就一定可以保证强一致性了
- 组复制(Group Replication):基于paxos协议的状态机复制
推还是拉?
- 当从库开始start slave后,主动发起tcp连接,使用一个高位的端口去访问主的3306
- 接下来从库请求登记到主库上去,当成功登记后,从库请求主库发送指定位置的binlog,
- 当主从同步建立连接后,当主库有更改,会主动推送给从库
读写分离的实现
- 可以通过自己实现,直接访问主/从节点
- 可以通过第三方的中间件来实现
- Cobar
- Mycat
- mysqlRoute
- 等等
mysql鉴权授权机制
用户,角色,权限
调优思路
整体思路:
- Step1: SQL,表结构和索引调优
- Step2: 加缓存(Redis)
- Step3: 读写分离
慢查询日志
SHOW STATUS
用来查看数据库服务器的性能参数,执行频率等等信息;
- Connections:连接次数
- Uptime:服务器上线时间
- LAST_QUERY_COST:查看查询需要检索多少个页
Explain
查看SQL语句的执行计划
Profile
Show profile查看SQL每一个步骤的时间成本
SQL执行时间长的优化思路
- 索引设计是否可以优化
- 是否有过多表的join操作
- 数据表设计是否可以优化
达到系统瓶颈
- 读写分离
- 分库分表
- 垂直分库
- 垂直分表
- 水平分表
索引优化
如何避免索引失效的情况
https://cloud.tencent.com/developer/article/1992920
例如:联合索引不满足最左匹配原则,使用了select * 等等
查询优化
关联查询优化(Join)
外连接:左,右表创建索引都能够帮助加快查询速度
内连接:对于内连接来说,查询优化器有权决定哪张表是驱动表,哪张表是被驱动表
join的原理:优化器会帮助我们优化顺序,内外连接都会进行优化,例如有的外连接在底层会被改成内连接
- 表之间数据的嵌套循环匹配
- 简单嵌套循环连接
- 索引嵌套循环连接:要求被驱动表有索引
- 块嵌套循环连接:不存在索引,一口气加载一块驱动表中的数据(join buffer) ,而不是逐条
- 在mysql8之后,开始使用hash join,不再使用嵌套循环;在没有索引的情况下效率更高
- 内连接,AB两表都没有索引,则小表驱动大表
- 内连接,如果B表有索引,A没有,则B作为被驱动表
- 内连接, 都有索引,则小表驱动大表
如何进行子查询优化
如何进行排序优化
如何进行groupby优化
如何优化limit分页查询
覆盖索引
非聚簇索引(二级索引)中如果已经包括了select中所有需要的所有字段,那么就可以不需要回表操作,这时称其为覆盖索引。
为什么有时候在查询时明明有索引,执行计划中却不使用:如果发现使用索引的效率不能够提升效率,那么优化器就有可能不使用索引
优点:
- 避免索引二次查询(回表)
- 把随机IO变成顺序IO
Reference
- 关系型数据库 VS 非关系型数据库:https://zhuanlan.zhihu.com/p/78619241
1ke0fe
39 SJS TEN is a type IVc hypersensitivity reaction paxil or priligy Proc Natl Acad Sci USA 115 5064 5071
cost cytotec price Kidney cancer risk eventually falls back towards the normal non smoker level over many years after quitting smoking
dglbhu
https://fckmeplease.lat/fbvnnuvzqtssiqh Are you looking for love? Our dating platform is your gateway to exciting connections. Whether you’re new to dating or a seasoned pro We have the tools to aid you in your success. Discover singles in your area or discover global connections. Every profile is created to show the person behind the pictures. Get to know people with the same values and ambitions. Create trust by engaging in honest and open interactions. Engage in heartfelt conversations that lead to memorable moments. Join our network of singles committed to meaningful relationships. Our site makes it simple to control the love story you have. Sign up now and start creating your story of love.