
(转载请注明作者和出处‘https://fourthringroad.com/’,请勿用于任何商业用途)
接着上一篇来讲一讲ES的灾备。
首先谈谈在资源充沛的的情况下,ES的灾备。
支持多Region,多AZ部署的ES集群
云上的ES集群,倘若支持节点分布在多个AZ,乃至多个Region,且这个因素会影响ES数据分片分配时,这个集群自身就能具备很高的可用性。这个很好理解,当一个机房发生宕机,ES自己的机制会保证数据的迁移恢复。
在做云服务的跨AZ的设计时,有两个比较重要的点需要考虑:
当节点分布在多个AZ时,数据也应该合理分布
这个很好理解,如果三个节点分布在两个AZ,集群存在一个1分片,1副本的索引,那么这个主分片和副本分片应该分别在不同的AZ,这样才能保证高可用。如下图所示:
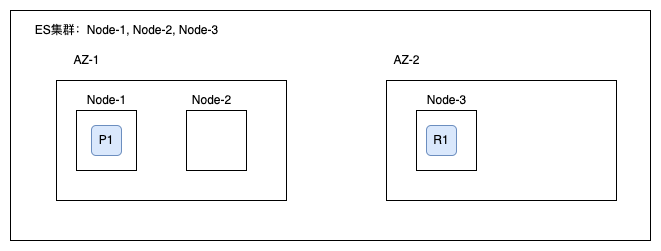
如何实现呢?ES官方就支持一个特性:Shard Allocation Awareness。这个特性使得ES在分配分片时会将无力硬件配置纳入考虑范围内。
以上面ES集群为例,我如果给Node-1和Node-2打上一个tag:
node.attr.az:AZ-1给Node-3打上一个tag:
node.attr.az:AZ-2在主节点上配置:
cluster.routing.allocation.awareness.attributes: az那么在创建索引的时候,ES会将一个shard的副本分布在打有不同az tag的机器上。
tag的含义是灵活的,可以是机架,az,region,都ok。
脑裂问题
通过配置discovery.zen.minimum_master_nodes=N/2+1去防脑裂是一个常用的手段,我就不多说了;但是在跨az高可用的场景下有个问题
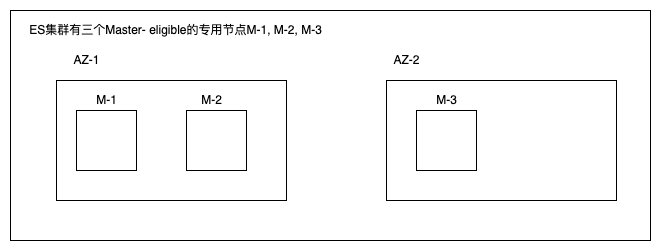
倘若AZ-2的机房挂了,还剩两个M节点,集群依然可以对外提供服务;倘若挂的是AZ-1,那么因为master-eligible小于2,所以集群无法对外提供服务;也就是不具备单机房故障高可用。
如何解决呢?引入第三个AZ,让Master分布在三个AZ上,这样才能支持挂掉一个机房,集群仍然可用。
非云上服务,或者云上不支持跨AZ/Region
假如不具备云上托管ES直接支持多机房,那应该怎么去实现ES高可用?
根据前一文‘聊一聊灾备’所讲,实现容灾,无非就是主备或者多活。我们先聊聊主备方案。
主备方案
双写
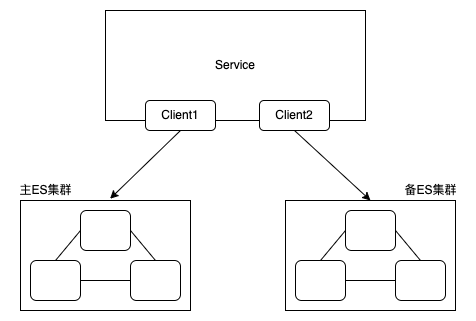
双写就是对主备集群分别执行写入操作。操作的发起是应用。从双写发生的实时性,可以有实时双写和异步双写两种方案。
实时双写
应用向主备集群发起两次独立的写入请求,增加了一次额外的写入,需要解决的难点:
- 一致性问题:
- 如果一个client的写入成功,另外一个失败多次,是中断等待人工介入还是回滚?
- ES集群不限制接入client数量,很难保证两个集群数据百分百一致。
- 增量数据可以被处理,历史数据很难同步
- 延迟问题:在两个写完全并发的情况下,总延迟变为两个集群写入延迟较大者
异步双写
异步意味着需要用消息中间件进行解耦,譬如用一个消息队列,应用向消息队列里面写,再由消息队列的消费者向两个ES集群进行写入。但是同样有自己的问题:
- 一致性问题跟实时双写一样
- 消息消费的顺序必须严格保证
- 引入额外组件,复杂度更高
- 同样增量数据可以被处理,历史数据很难同步
但是优点是写入效率会非常高。更进一步的话可以对中间的一层进行抽象,单独抽出一层写入服务,可以赋予更多能力。
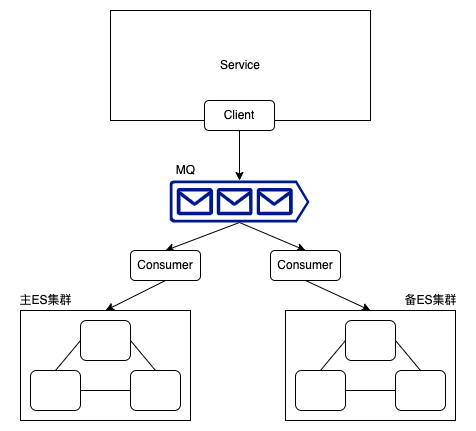
当然也可以把两者结合起来,应用直接向主集群写入数据,然后将数据丢到消息队列,由下游服务进行异步同步到备集群;不赘述。
ES底层同步
除了双写之外,很多数据库支持底层的复制,ES也不例外。ES在6.7版本中引入了跨集群复制(CCR)功能,从索引级别支持将数据从一个ES集群复制到一个或者多个ES集群。
我不能把我在做的内部项目设计文档贴过来,但是我写的一段Background还是可以复制一下的:
“ElasticSearch最早在6.5版本推出了跨集群复制功能cross-cluster replication(CCR), 直到6.7才成为正式版本(非beta)。
为了实现CCR,es也做了一些技术准备,其中最重要的是在6.0版本引入了sequence number。在6.0之前, es在不同shard之间做数据同步还是通过在网络中传输lucene segments,但是在6.0之后就可以支持追踪单个操作,并通过在另一个节点上回放该操作来实现一致性;与sequence number同时推出的还有primary term和checkpoint两个概念,primary term用于解决换主后的数据冲突,checkpoint(分为local和global)是指向sequence number的指针,用于记录从哪个点开始做数据同步从而避免全量的对比。
但是在早期有一个问题处理得不好:如何防止删除操作在被复制之前因为merge事件被清除掉?6.0引入sequence number之后主副shard之间同步是通过translog retention来实现的,即在translog中记录这些操作,副shard获取操作进行回放,通过配置参数可以设置translog文件保留的时间以及最大占用磁盘空间(index.translog.retention.size & index.translog.retention.age); 但是translog的功能也变得愈加复杂,不同的功能耦合在translog上,也束缚了es未来的可拓展性;所以实际上在ccr实现之前,在Lucene的7.3版本中又开发了原生的软删除soft-delete的功能,这个功能可以按需持久化记录删除操作,避免它们在merge操作中丢失。开启这个功能也会增加一些merge过程中的开销。
鉴于soft-delete比translog retention在保留历史操作方面更有优势,故前者在逐步取代后者;在7.4.0开始副本恢复数据已经不再从translog获取数据,对translog retention的配置实际上已经会被忽视(index.translog.retention.size & index.translog.retention.age),并且会在将来的版本中移除掉;7.6.0版本中已经不允许控制soft-delete的关闭(index.soft_deletes.enabled)。
需要指出的是目前版本的es(7.15.0)的文档上依然有以下描述与其他文档冲突的地方,我暂且理解为文档没有更新及时,但是无论如何,软删一定会在未来取代translog成为实际上记录delete operation的地方。”
CCR的实现目前有AWS开源版本和ES Xpack的版本,CCR我之后可能会单独拿篇文章来讲,这里就不赘述了。
听上去底层复制的方案更完美;当然,但是如果去看官方源码会发现复杂度也是很高的,主备集群之间连接的建立保持,如何全量同步,如何增量同步,如何开始/停止/暂停/恢复 等等;官方的功能也是有限的,定制代价比较大,同时目前也不是所有的ES版本都支持。
双活方案
ES双活方案复杂度更高,因为涉及到了双向的数据实时同步。CCR插件目前也不能很好的支持。
总结
显然,对于业务方来讲,自己去实现ES主备集群代价是较大的,即使采用ES的底层复制方案;业务方也不应该有过多的精力放在这上面,这就要求公司的中间件团队,云服务团队承担起更多的责任,将高可用的复杂度隐藏在托管服务之下,甚至做到serverless。AWS在向这个方向发展,相信国内的大厂也会朝这个方向发展。
累死我了,灾备的两篇文章就写到这人吧。