
接上文
(转载请注明作者和出处‘https://fourthringroad.com/’,请勿用于任何商业用途)
服务–service
服务是一种给一组pod提供一个统一接入点的资源。
service通过标签收集到一组pod,client可以通过service的IP+port访问到底层的pod;这其中还包括了负载均衡的策略在里面。
service一旦被分配IP,可以保证这个IP不会变化。
Service提供四层lb能力,不能提供7层。
服务可以配置会话的亲和性:
sessionAffinity:ClientIP
这样同一个IP的请求会被转发到同一个后端pod
服务发现
实现服务发现的两层含义:
- 一个vip/域名后挂在多个动态的后端
- 服务之间可以通过一个服务来发现彼此的vip/域名(实际上是通过CoreDNS实现的)
如何通过DNS发现服务:
通过FQDN(fully qualified domain name )可以直接访问一个服务:
Service-name.default.svc.cluster.local
需要注意:
- 端口是默认信息,如果用httpclient访问,默认就是80/443;有必要需要自己指定
- 如果在同一个namespace下面,可以直接同service-name访问
集群内部pod之间通过服务访问:
ClusterIP模式:最简单的模式;直接创建一个service;直接IP/FQDN 就可以访问
集群内部pod访问外部服务
- Service资源关联了一个Endpoint资源,里面是后端的ip 列表;如果暴露的是内部pods,那么是selector关联到的所有pod ip;如果手动配置外部服务的ip,那么service等同于暴露外部服务的访问了。
- 更简单的方式:通过type: ExternalName直接指向一个外部资源FQDN: www.xxx.com
将服务暴露给外部客户端
1. Service type = nodeport:
会将node上开启一个port,并将这个port的流量重定向到service本身
apiVersion: v1
kind: Service
metadata:
name: my-nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30123 #如果省略会随机分配
selector:
run: my-nginx上述配置可以通过node_ip:30123 访问到service暴露的服务
2. service type = LoadBalancer
以nodeport为基础;会在云基础设施中创建一个独立LB资源,这个LB拥有可公开访问的独立IP地址;LB会将流量转发到node port,剩下的流程跟nodeport相同。
apiVersion: v1
kind: Service
metadata:
name: my-nginx
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
run: my-nginx创建完成之后,一个通过 get svc 查看external-ip。
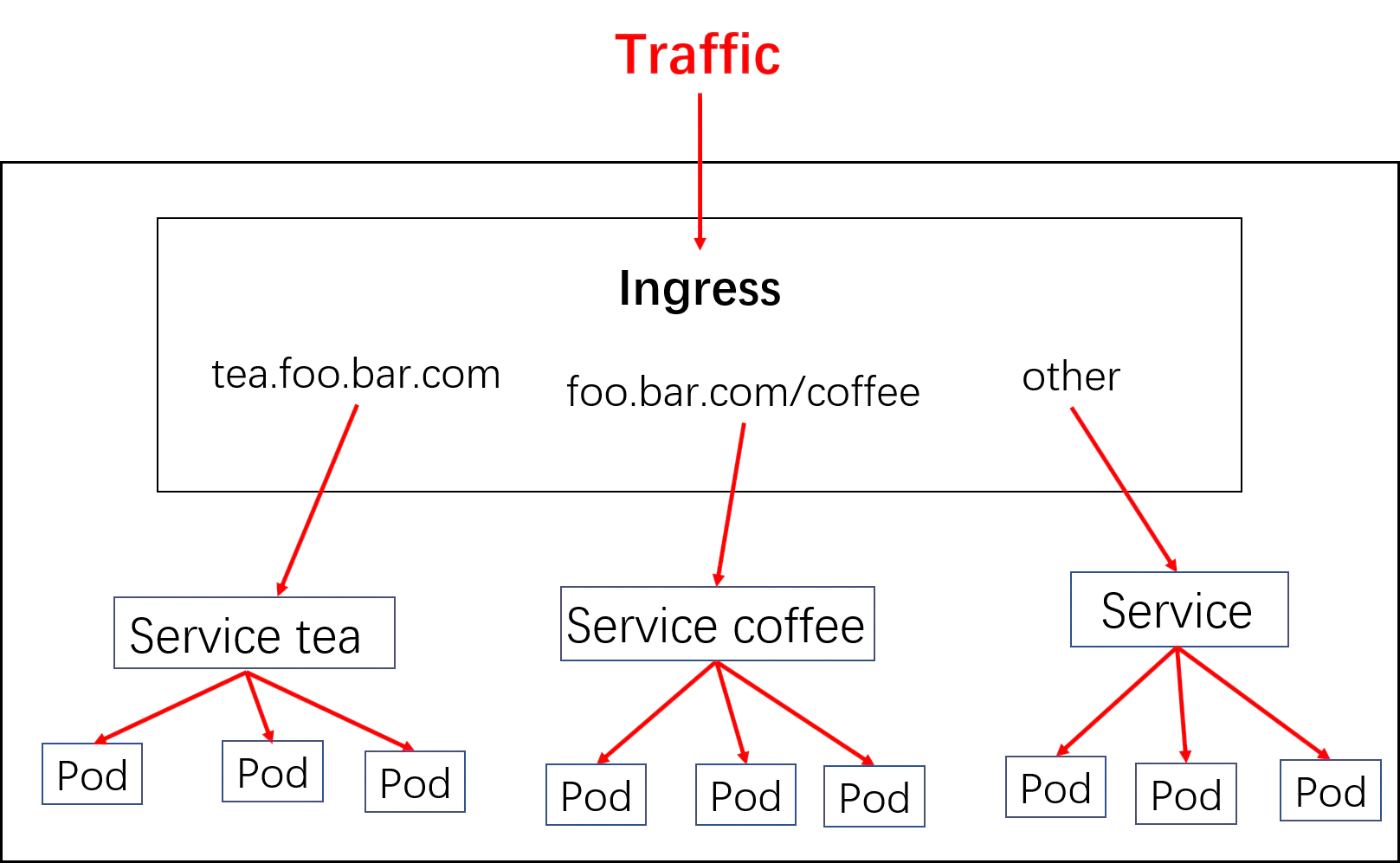
3. Ingress
LB模式,给每一个服务都生成一个负载均衡器以及独立IP。如果想做到七层(http)负载均衡呢?如果想提供基于cookie的会话亲和性呢?
Headless Service-无头服务
如果希望连接到所有pod,则需要获得所有pod的IP;如果创建Service的时候不生成IP,则DNS查询服务时(nslookup xx.default.svc.cluster.local),会返回所有pod的IPs;
配置: clusterIP:none
STS必须使用无头服务
负载均衡:
通常使用RoundRobin
底层实现?
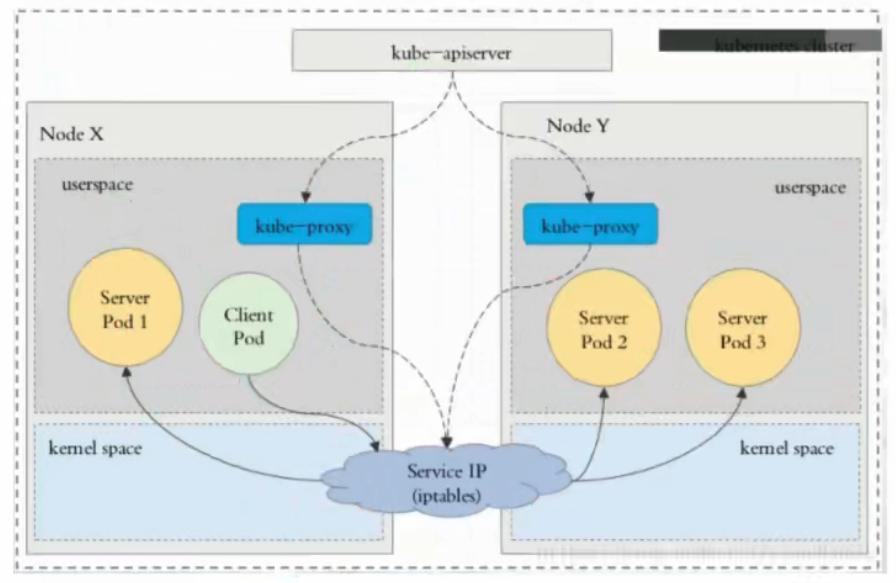
每个 Node 运行一个 kube-proxy 进程。 kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,
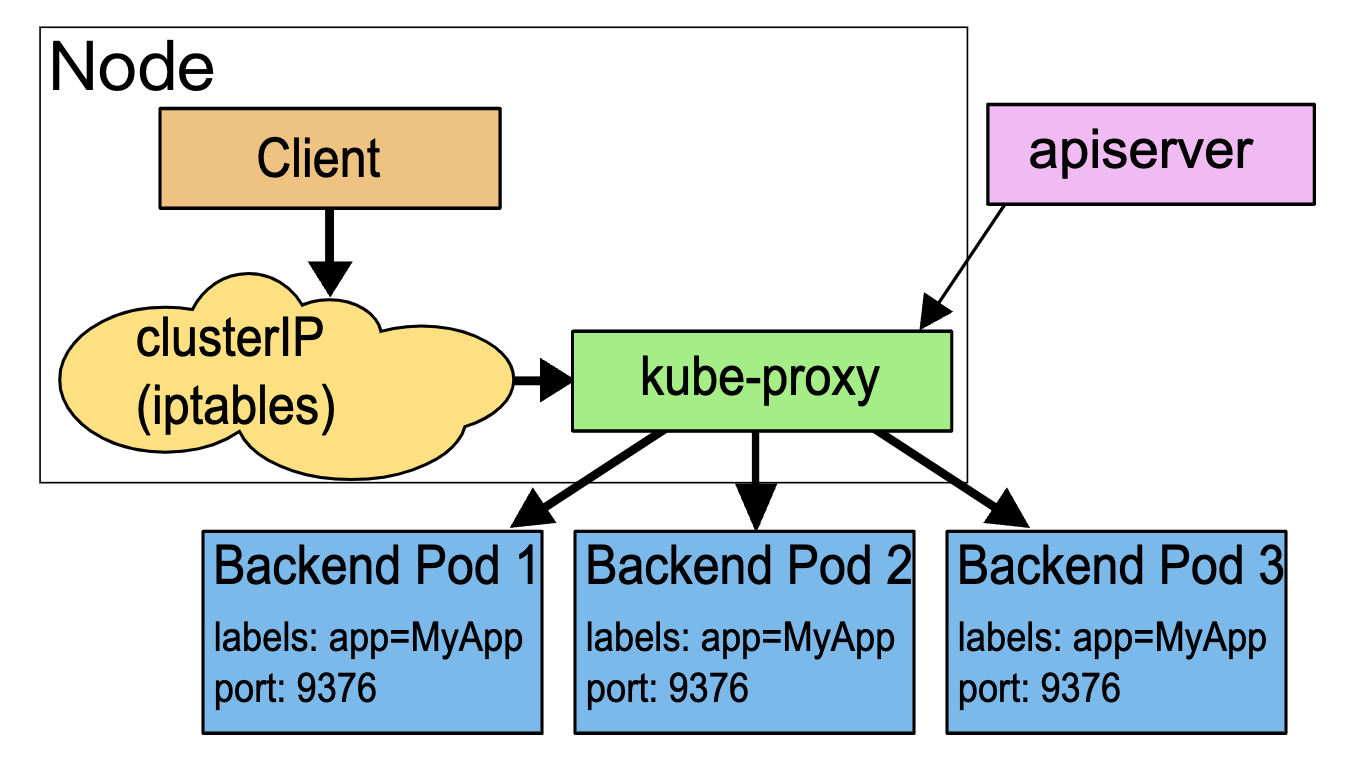
1. Userspace
这种模式,kube-proxy 会监视 Kubernetes 控制平面对 Service 对象和 Endpoints 对象的添加和移除操作。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被proxy转发到 Service 的后端 Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个后端 Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
最后,它配置 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP) 和 Port 的请求,并重定向到代理端口,代理端口再代理请求到后端Pod。
默认情况下,用户空间模式下的 kube-proxy 通过轮转算法选择后端。
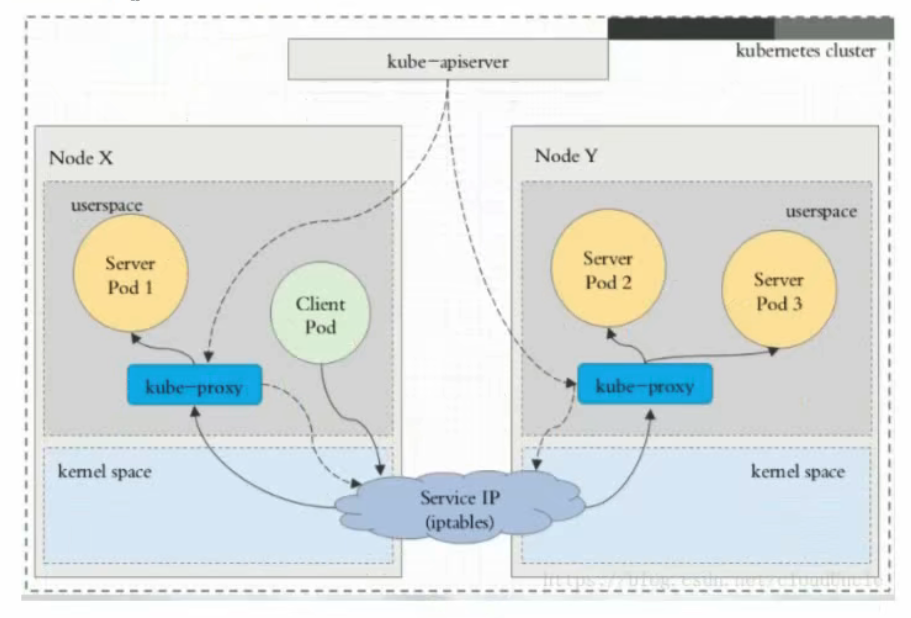
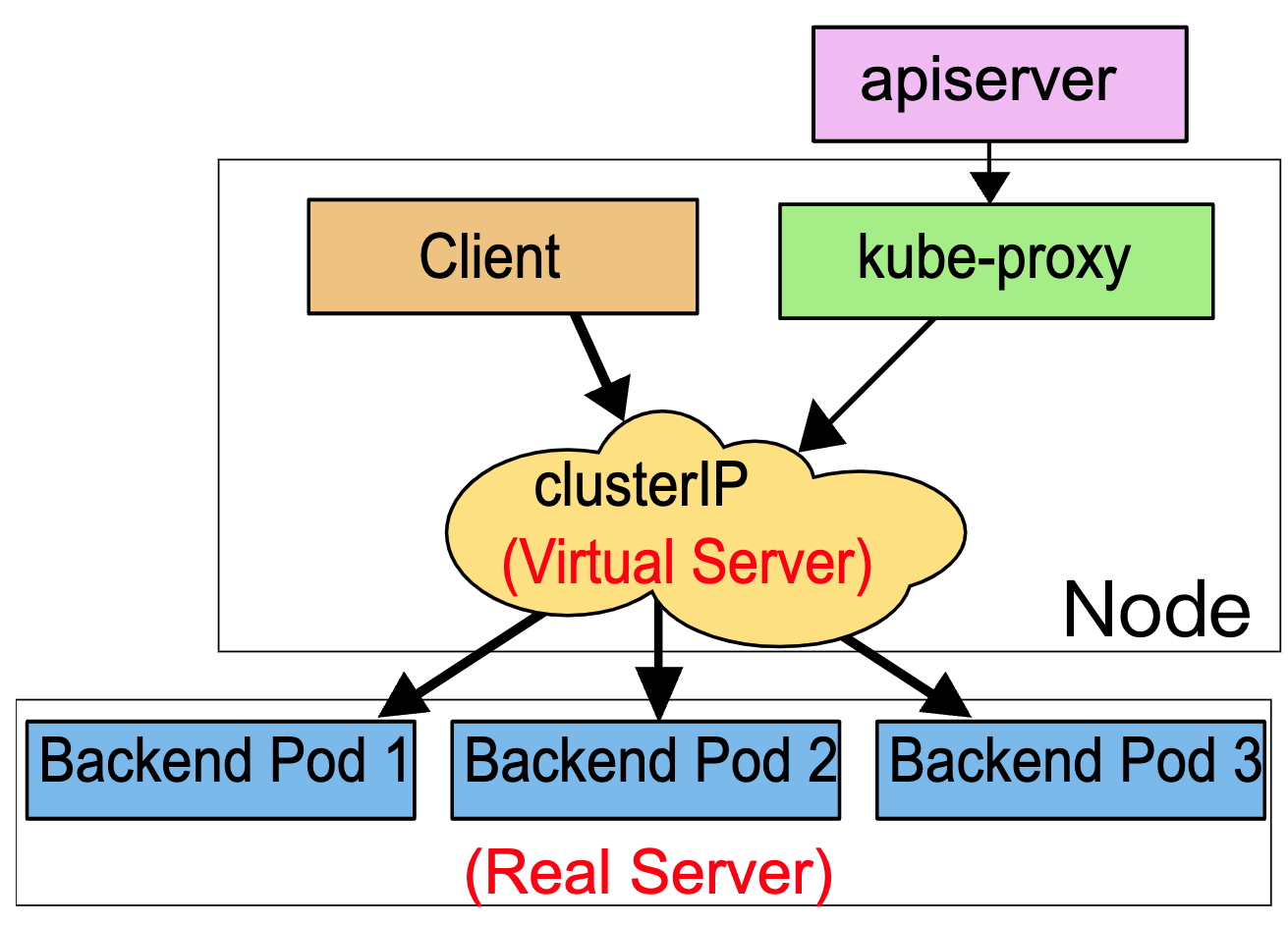
2. Iptables
iptables是基于包过滤的防火墙工具
关于iptables原理:https://cloud.tencent.com/developer/article/1632776
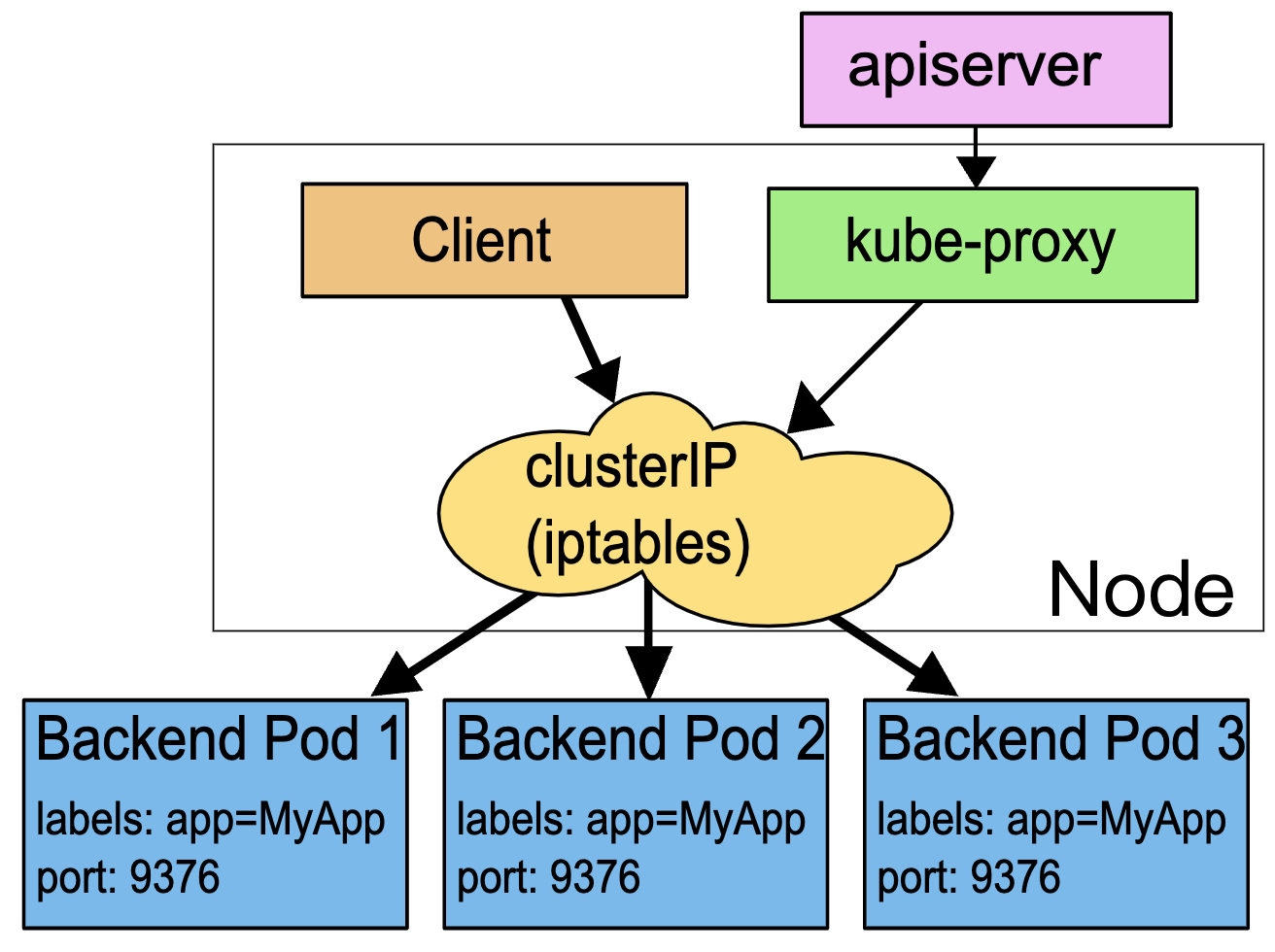
这种模式,kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会配置 iptables 规则,从而捕获到达该 Service 的 clusterIP 和端口的请求,进而将请求重定向到 Service 的一组后端中的某个 Pod 上面(RR也是iptables实现的)。对于每个 Endpoints 对象,它也会配置 iptables 规则,这个规则会选择一个后端组合。
默认的策略是,kube-proxy 在 iptables 模式下随机选择一个后端。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应, 则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
你可以使用 Pod 就绪探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy 发送到已知已失败的 Pod。
3. Ipvs:1.14版本默认使用
在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 提供了更多选项来平衡后端 Pod 的流量。 这些是:
- rr:轮替(Round-Robin)
- lc:最少链接(Least Connection),即打开链接数量最少者优先
- dh:目标地址哈希(Destination Hashing)
- sh:源地址哈希(Source Hashing)
- sed:最短预期延迟(Shortest Expected Delay)
- nq:从不排队(Never Queue)
ConfigMap
A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume.
A ConfigMap allows you to decouple environment-specific configuration from your container images, so that your applications are easily portable.
例子:
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true 如何消费:
There are four different ways that you can use a ConfigMap to configure a container inside a Pod:
- Inside a container command and args
- Environment variables for a container
- Add a file in read-only volume, for the application to read
- Write code to run inside the Pod that uses the Kubernetes API to read a ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# Define the environment variable
- name: PLAYER_INITIAL_LIVES # Notice that the case is different here
# from the key name in the ConfigMap.
valueFrom:
configMapKeyRef:
name: game-demo # The ConfigMap this value comes from.
key: player_initial_lives # The key to fetch.
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# You set volumes at the Pod level, then mount them into containers inside that Pod
- name: config
configMap:
# Provide the name of the ConfigMap you want to mount.
name: game-demo
# An array of keys from the ConfigMap to create as files
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"ConfigMap的更新
- 如果是挂载volume支持热更新
- 如果是env,则不支持热更新
Secret
A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in a container image. Using a Secret means that you don’t need to include confidential data in your application code.
我个人认为:应该尽量避免使用ConfigMap和Secret;而是使用一些第三方微服务在k8s环境中提供相应的功能;这样能够保证与k8s底层解耦。方便未来的迁移。
用途:
- As files in a volume mounted on one or more of its containers.
- As container environment variable.
存储 kubelet从docker registry 拉取镜像时使用的密钥;(imagePullSecrets)
apiVersion: v1
data:
username: YWRtaW4=
password: MWYyZDFlM mU2N2Rm
kind: Secret
metadata:
annotations:
....用法很简单:创建一个secret资源,里面有加密过的strings(base64加密),但在pod中使用时可以直接使用解密后的数据。
疑问:base64真的是一个安全的加密方案吗?
存储
Volumes
容器中的文件的存在是短暂的,一旦容器被kubelet重启,所有的数据都会被丢掉(以一个clean state重启);另外一个问题是一个pod中的容器如何共享文件的问题;这两个问题都可以通过卷来解决。
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。 对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
卷的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。 所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。
容器中的进程看到的文件系统视图是由它们的 容器镜像 的初始内容以及挂载在容器中的卷(如果定义了的话)所组成的。卷挂载在镜像中的指定路径下。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
几个常用的卷类型:
Secret
Configmap
这两个不赘述,都可以挂载到pod上;
emptyDir
当 Pod 分派到某个 Node 上时,emptyDir 卷会被创建,并且在 Pod 在该节点上运行期间,卷一直存在。 就像其名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
注意:容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的
取决于你的环境,emptyDir 卷存储在该节点所使用的介质上;这里的介质可以是磁盘或 SSD 或网络存储。但是,你可以将 emptyDir.medium 字段设置为 “Memory”,以告诉 Kubernetes 为你挂载 tmpfs(基于 RAM 的文件系统)
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}hostPath
hostPath 卷能将主机节点文件系统上的文件或目录挂载到你的 Pod 中
这是一共比较通用的解决方案,譬如你在主机上挂载了aws 的ebs,当然可以通过hostPath的形式将ebs中的一个目录挂载到pod中
不过最新的文档已经不推荐使用hostpath了:
HostPath 卷存在许多安全风险,最佳做法是尽可能避免使用 HostPath。 当必须使用 HostPath 卷时,它的范围应仅限于所需的文件或目录,并以只读方式挂载。
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# 宿主上目录位置
path: /data
# 此字段为可选
type: Directory其他还有一些类型,例如:
awsElasticBlockStore
awsElasticBlockStore 卷将 Amazon Web服务(AWS)EBS 卷 挂载到你的 Pod 中。与 emptyDir 在 Pod 被删除时也被删除不同,EBS 卷的内容在删除 Pod 时会被保留,卷只是被卸载掉了。 这意味着 EBS 卷可以预先填充数据,并且该数据可以在 Pod 之间共享。
持久卷:PV-PVC
原理非常简单:
- 把一个存储映射到一个PV(持久卷)资源;它们拥有独立于任何使用 PV 的 Pod 的生命周期;
- 在pod中申明一个PVC:持久卷申领(PersistentVolumeClaim,PVC)表达的是用户对存储的请求;
- 系统会根据pod的pvc去匹配一个核实的pv资源并挂载到pod中的容器中。
pvc的命名规则:(volumeClaimTemplates.name)-(pod name);每一个pod都会有一个自己特有的pvc;可以通过get pvc查看
如何释放pv
使用pv-pvc后,即使删除相关pods(STS);再次创建之后,存储数据依然存在并且能够正常访问。pvc在选择了retain模式之后,只有手动删除才会真的被删除。一旦删除pvc,相关的pv就会变成released状态,还需要手动删除pv(kubectl edit pv xxx)中的绑定信息才能变成available状态并可供其他的pod挂载。
调度,抢占(preemption)和驱逐(Eviction)
调度
调度 是指将 Pod 放置到合适的 Node 上,然后对应 Node 上的 Kubelet 才能够运行这些 pod。
模块:kube-scheduler;用户也可以自己实现调度器来取代这个原有的组件。可以通过对schedulerName: default-scheduler 进行修改,使用自己定义的调度器。
满足一个 Pod 调度请求的所有 Node 称之为 可调度节点。 如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在 未调度状态直到调度器能够找到合适的 Node。
调度的流程:过滤&打分
调度器先在集群中找到一个 Pod 的所有可调度节点(过滤),然后根据一系列函数对这些可调度节点打分(打分), 选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
也可以称这两个过程为预选和优选;
There are two supported ways to configure the filtering and scoring behavior of the scheduler:
- Scheduling Policies allow you to configure Predicates(断言) for filtering and Priorities for scoring.
- Scheduling Profiles(配置) 允许你配置实现不同调度阶段的插件, including: QueueSort, Filter, Score, Bind, Reserve, Permit, and others. You can also configure the kube-scheduler to run different profiles.
Predicate有一系列的算法可以使用:
- 节点上剩余资源是否满足需求
- 节点上已经使用的port是否冲突
- 节点的label是否满足需求
- 等等
predicate无法得到满足,pod会一直处在pending状态
预选过程之后获得一系列节点后,就会进行优选:
- CPU和Memory使用率越低,权重越高
- CPU和Mem使用率越接近,权重越高
- 已经有镜像(不需要重复拉取),权重越高
- 等等
可以通过以下方式控制一个pod落在哪个node上面:
- 通过nodeSelector来选择node标签
- 指定亲和性与反亲和性(Affinity and anti-affinity)
- 直接指定nodeName(PodSpec.nodeName)
Scheduler在bind一个pod到相关node之后,对应节点上的kubelet会监听(watch)到这个事件,并在node上创建相关容器。
1. 通过nodeSelector来选择node标签
Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。这个标签通常是云服务提供商打在node上的。
2. 指定亲和性与反亲和性(Affinity and anti-affinity)
1. (pod亲和)你可以使用节点上(或其他拓扑域中)运行的其他 Pod 的标签来实施调度约束, 而不是只能使用节点本身的标签。这个能力让你能够定义规则允许哪些 Pod 可以被放置在一起。
2. (节点亲和)可以指定具备某些标签的节点,也可以标明某规则是“软需求”或者“偏好”,这样调度器在无法找到匹配节点时仍然调度该 Pod。当然也可以要求严格匹配,否则不调度。
对于例子1:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0- 调度器必须将 Pod 调度到具有 topology.kubernetes.io/zone=V 标签的节点上,并且集群中至少有一个位于该可用区的节点上运行着带有 security=S1 标签的 Pod。
- 如果同一可用区中存在其他运行着带有 security=S2 标签的 Pod 节点, 并且节点具有标签 topology.kubernetes.io/zone=R,Pod 不能被调度到该节点上。
topologyKey可以是服务器,机架,机房,az,region等等,其本质只是node的一个标签而已。
对于例子2:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0- 节点必须包含键名为 kubernetes.io/os 的标签,并且其取值为 linux。
- 节点 最好 具有键名为 another-node-label-key 且取值为 another-node-label-value 的标签。
如果operator使用了NotIn 和 DoesNotExist 可用来实现节点反亲和性行为。
污点(taint)和容忍度(toleration)
节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint)则相反——它使节点能够排斥一类特定的 Pod。
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。
应用场景:
- 如果您想将某些节点专门分配给特定的一组用户使用,您可以给这些节点添加一个污点
- 在部分节点配备了特殊硬件(比如 GPU)的集群中, 我们希望不需要这类硬件的 Pod 不要被分配到这些特殊节点,以便为后继需要这类硬件的 Pod 保留资源。
- 基于污点的驱逐: 这是在每个 Pod 中配置的在节点出现问题时的驱逐行为,污点的 effect 值 NoExecute会影响已经在节点上运行的 Pod,能够驱逐pod;比如,一个使用了很多本地状态的应用程序在网络断开时,仍然希望停留在当前节点上运行一段较长的时间, 愿意等待网络恢复以避免被驱逐。
effect的三个选项:
- Noschedule
- preferNoSchedule
- noExecute:不调度,且会驱逐已经存在的pod
例子:
kubectl taint nodes node1 key1=value1:NoSchedule
给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。
如果一个pod在spec中配置如下容忍度,则可以被分配到node1
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果
PreferNoSchedule。 这是“优化”或“软”版本的 NoSchedule —— 系统会 尽量 避免将 Pod 调度到存在其不能容忍污点的节点上, 但这不是强制的。
master节点天生就被打了污点,所以普通的pod不会被调度到master集群上;如果将其污点改成preferNoSchedule,那么在资源不足时,也可以将pod部署到master上了。
抢占
Pod 可以有 优先级。 优先级表示一个 Pod 相对于其他 Pod 的重要性。 如果一个 Pod 无法被调度,调度程序会尝试抢占(驱逐)较低优先级的 Pod, 以使悬决 Pod 可以被调度。
PriorityClass 是一个无名称空间对象,它定义了从优先级类名称到优先级整数值的映射。将它跟pod绑定就可以指定pod的优先级。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority- 当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序, 并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。 因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。 如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
- Pod 被创建后会进入队列等待调度。 调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。 如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。 让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。 如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
驱逐
节点压力驱逐:
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的 CPU、内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
API 发起的驱逐
API 发起的驱逐是一个先调用 Eviction API 创建 Eviction 对象,再由该对象体面地中止 Pod 的过程。
你可以通过直接调用 Eviction API 发起驱逐,也可以通过编程的方式使用 API 服务器的客户端来发起驱逐, 比如 kubectl drain 命令。 此操作创建一个 Eviction 对象,该对象再驱动 API 服务器终止选定的 Pod。
K8s operator的二次开发
https://kubernetes.io/docs/concepts/extend-kubernetes/#extension-patterns
https://zhuanlan.zhihu.com/p/246550722
https://www.bilibili.com/video/BV1oL411F7hN
People who run workloads on Kubernetes often like to use automation to take care of repeatable tasks. The Operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides.
operator核心就是将运维操作自动化;
譬如运维人员在k8s创建一个ES集群时,有很多需要依次执行的步骤:
- 创建管理容器
- 创建master容器
- 创建协调节点容器
- 创建数据节点
- 创建kibana节点
- 等等等等
这些个步骤的自动化可以放在k8s外,当然也可以通过k8s的operator模式来实现-“operator 是一种 kubernetes 的扩展形式,可以帮助用户以 Kubernetes 的声明式 API 风格自定义来管理应用及服务,operator已经成为分布式应用在k8s集群部署的事实标准了,在云原生时代系统想迁移到k8s集群上编写operator应用是必不可少的能力”
使用operator之后,在管理云资源时,可以通过声明式API,而不是命令式的方式。
下面画了一个我理解的的大概原理:
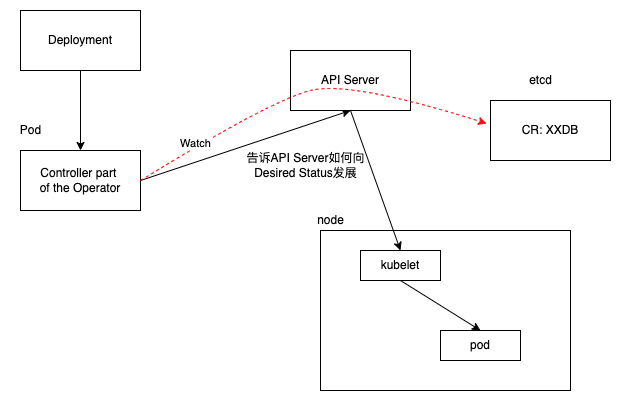
Operator:其实就是定义一个新的控制回路(controller),这个控制回路会创建,监控并控制一个自定义资源(CR)的状态;
CR是什么:
在 Kubernetes 中我们使用的 Deployment, DamenSet,StatefulSet, Service,Ingress, ConfigMap, Secret 这些都是resource资源;当我们在使用中发现现有的这些资源不能满足我们的需求的时候,Kubernetes 提供了自定义资源(Custom Resource)和 operator为应用程序提供基于 kuberntes 扩展。
如何部署Operator
其实就是将CRD(definition) 和 controller 添加到集群中。(使支持)
这样可以用kube create/get/edit直接对这个资源进行操作;与内建controller不同的是,这个控制器会在控制平面之外运行。
一个postgres-operator的CRD:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: postgresqls.acid.zalan.do
labels:
app.kubernetes.io/name: postgres-operator
annotations:
"helm.sh/hook": crd-install
spec:
group: acid.zalan.do
names:
kind: postgresql
listKind: postgresqlList
plural: postgresqls
singular: postgresql
shortNames:
- pg additionalPrinterColumns:
- name: Team
type: string
description: Team responsible for Postgres CLuster
JSONPath: .spec.teamId
- name: Version
type: string
description: PostgreSQL version
JSONPath: .spec.postgresql.version
- name: Pods
type: integer
description: Number of Pods per Postgres cluster
JSONPath: .spec.numberOfInstances
- name: Volume
type: string
description: Size of the bound volume
JSONPath: .spec.volume.size
...
为了方便Operator开发,有一些工具会为我们搭建脚手架,例如:
- operator SDK —— operator framework,是 CoreOS 公司开发和维护的用于快速创建 operator 的工具,可以帮助我们快速构建 operator 应用,
- KUDO (Kubernetes 通用声明式 Operator)
- kubebuilder,kubernetes SIG 在维护的一个项目
- Metacontroller,可与 Webhook 结合使用,以实现自己的功能。
重要函数入口:reconcile()
Helm
以chart包的形式管理部署k8s的程序;
一个chart包包括一系列的文件资源,并支持模版形式方便变量的注入。
https://www.jianshu.com/p/4bd853a8068b
一些常用kubectl命令
kubectl apply -f xx.yml
kubectl create -f xx.yml
kubectl cluster-info
kubectl get nodes
Kubectl describe node (NODE_ID)
Kubectl get pod
kubectl get pods –show-lables
kubectl get pods xxx -o yaml
Kubectl get pod -o wide 查看详细信息
kubectl lable pod xxx foo=bar
kubectl describe pod xxx
kubectl delete pod xxx
kubectl log xxx
kubectl log xxx -c 指定容器
Kubectl get services
kubectl exec xxx -it — /bin/sh 进入容器
kubectl delete deployment —all
kubectl explain rs -》 查看rs的文档
kubectl exec xx-pod — curl -s http://xxx 在pod内部执行一个Linux命令
kubectl exec -it xx /bin/bash -》 进入容器
如何指定namespace: -n xxxx
kubectl apply -f xx.yml
kubectl create -f xx.yml
kubectl cluster-info
kubectl get nodes
Kubectl describe node (NODE_ID)
Kubectl get pod
kubectl get pods –show-lables
kubectl get pods xxx -o yaml
Kubectl get pod -o wide 查看详细信息
kubectl lable pod xxx foo=bar
kubectl describe pod xxx
kubectl delete pod xxx
kubectl log xxx
kubectl log xxx -c 指定容器
Kubectl get services
kubectl exec xxx -it — /bin/sh 进入容器
kubectl delete deployment —all
kubectl explain rs -》 查看rs的文档
kubectl exec xx-pod — curl -s http://xxx 在pod内部执行一个Linux命令
kubectl exec -it xx /bin/bash -》 进入容器
如何指定namespace: -n xxxx
This is really interesting, You’re a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks! Thanks Seo company India https://sites.google.com/view/seohawk/home
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed surfing around your blog posts. After all I will be subscribing to your rss feed and I hope you write again very soon!
Seo company India liked the valuable information you provide in your articles. I?ll bookmark your blog and check again here frequently. I’m quite sure I will learn many new stuff right here! Good luck for the next! read this http://www.empregosaude.pt/en/author/stanley/
We’re a group of volunteers and starting a new scheme in our community. Your site offered us with valuable information to work on. You’ve done an impressive job and our whole community will be thankful to you.