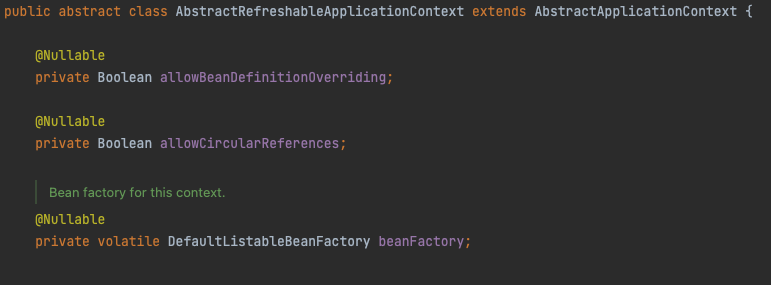
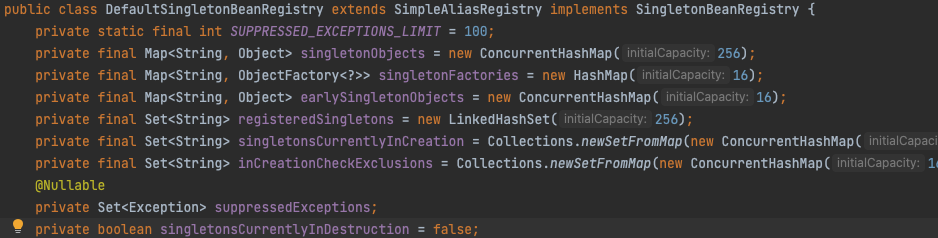
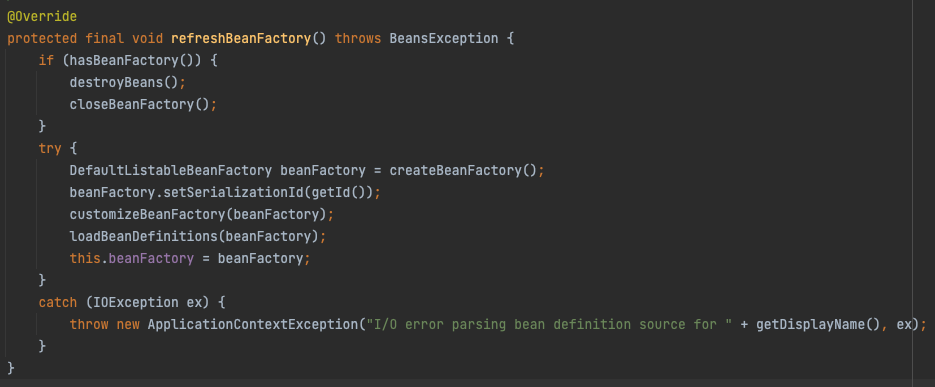
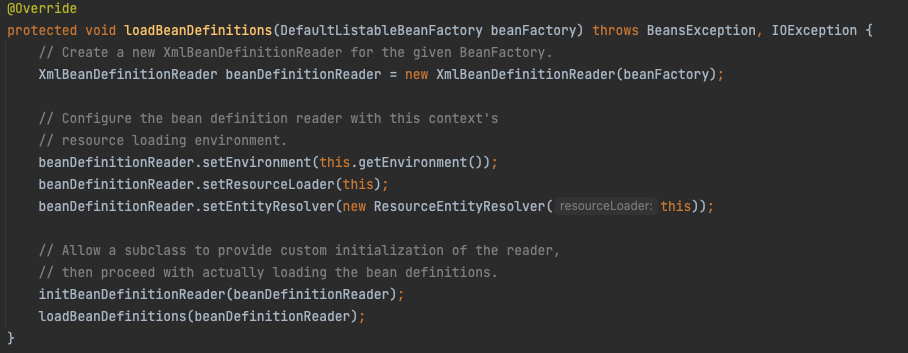
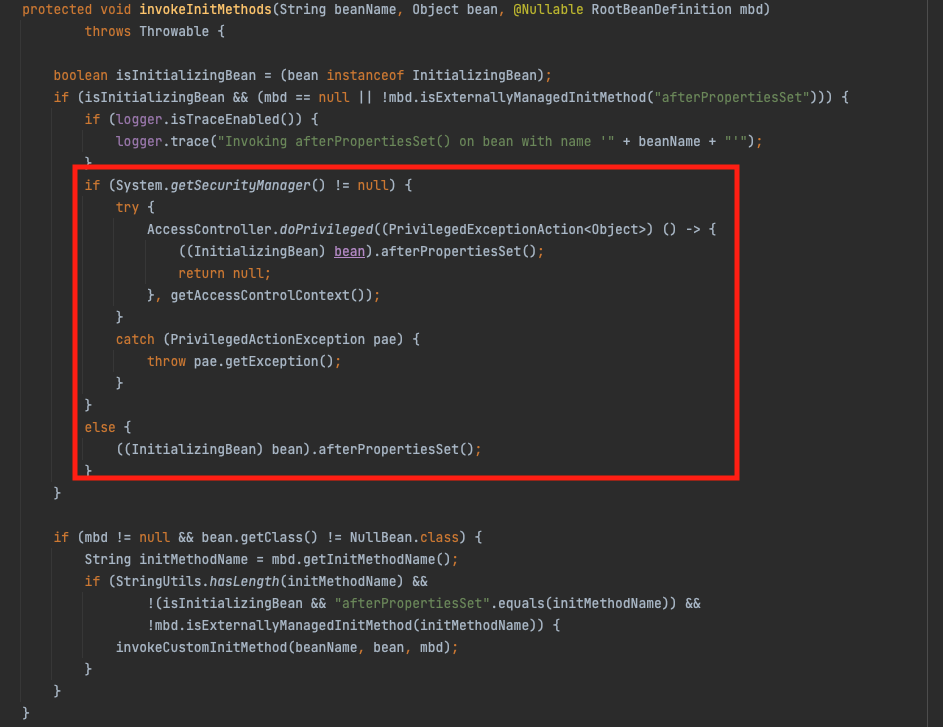
整理一下之前的笔记
概述
我们常常讨论的分布式系统是什么?
- 系统分布在多台服务器上
- 系统维护数据-是stateful的
常见的分布式系统
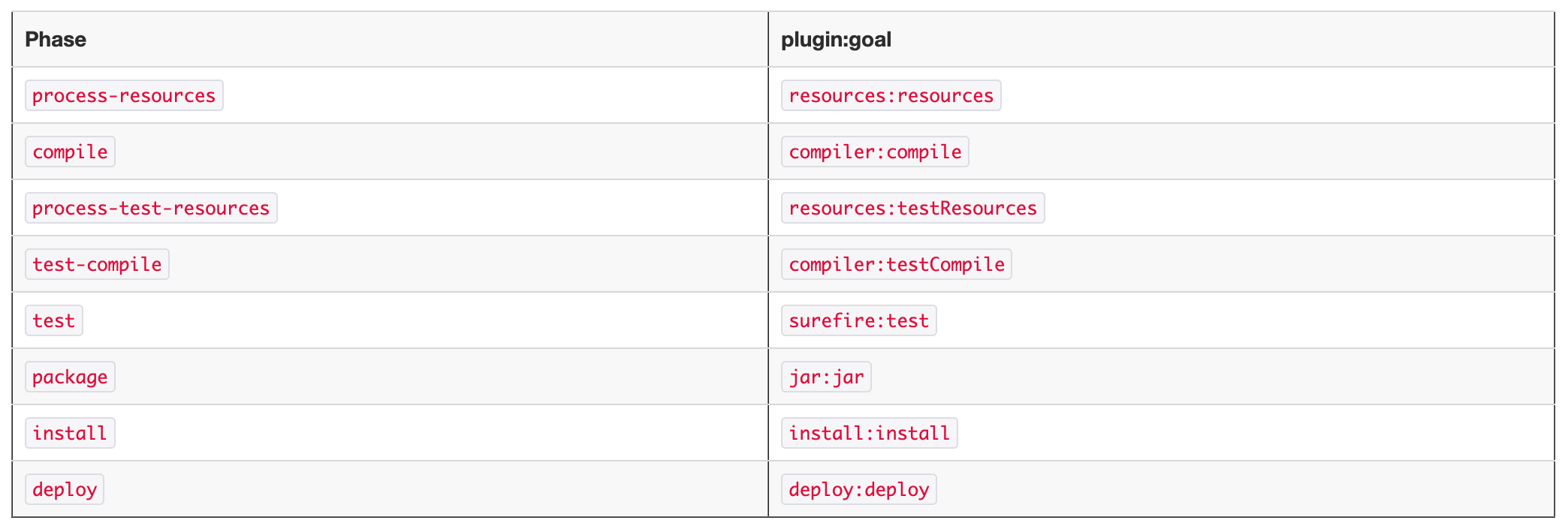
Type of platform/framework Example
Databases Cassandra, HBase, Riak
Message Brokers Kafka, Pulsar
Infrastructure Kubernetes, Mesos, Zookeeper, etcd, Consul
In Memory Data/Compute Grids Hazelcast, Pivotal Gemfire
Stateful Microservices Akka Actors, Axon
File Systems HDFS, Ceph常见问题
- 程序中断
- 数据不丢失:往往flush数据到storage是一个费时费力的操作,如何保证内存中的数据在程序意外退出时不丢失就是一个难点,一个常见的solution就是Write-Ahead Log(or Transaction Log, or Commit Log),将每条数据以append-only的形式快速持久化到一个日志之中。
- 数据可用性:常用的手段是数据在多台服务器上冗余存储(副本);
- 网络延迟/网络分区
- 服务器如何确认彼此还存活:HeartBeat – 按照周期发送心跳请求,来确认彼此的存活。
- 解决脑裂问题:Quorum-保证‘大多数’make the decision.
- 解决数据一致性问题:某些节点上数据已经更新,但是某些节点上因为网络和处理延迟,还没有存储着旧数据;解决方式之一是Leader and Followers模式;同时可以利用High-Water Mark来标记事务日志中哪些数据是可以满足一致性前提来提供给用户的。
- 程序暂停/挂起/卡住
- 我们需要一个机制来检测 out-of-date leaders:Generation Clock,对于来自过时的主节点的请求,应当抛弃使用。
- 系统时钟/消息顺序
- 分布式系统的时钟同步通常利用NTP服务,但是可能因为网络问题而中断,所以系统时钟无法用来保证消息的顺序性;
- 如何标记消息的顺序:Lamport Clock-Generation Clock,通常是一个sequence number;
- Hybrid-Clock使用系统时间以及一个SN来标记顺序;
- 如何检测对于不同副本上的同一个值的并发更新呢?Version Vector就是用来检测冲突的。Versioned Value也是一个相关的模式
分布式一致性Distributed Consensus
Consensus refers to a set of servers which agree on stored data, the order in which the data is stored and when to make that data visible to the clients.
算法:Paxos,Raft,Zab, Two-phased commit等
Paxos describes a few simple rules to use two phase execution, Quorum and Generation Clock to achieve consensus across a set of cluster nodes even when there are process crashes, network delays and unsynchronized clocks.
相关技术还有:Replicated Log(也叫做State machine Replication),Lease,State Watch,Consistent Core
事务日志 Write-Ahead Log
The Write Ahead Log is divided into multiple segments using Segmented Log. This helps with log cleaning, which is handled by Low-Water Mark. Fault tolerance is provided by replicating the write-ahead log on multiple servers. The replication among the servers is managed using the Leader and Followers pattern and Quorum is used to update the High-Water Mark to decide which values are visible to clients.
数据分区
Consensus algorithms are useful when multiple cluster nodes all store the same data. Often, data size is too big to store and process on a single node. So data is partitioned across a set of nodes using various partitioning schemes such as Fixed Partitions or Key-Range Partitions. To achieve fault tolerance, each partition is also replicated across a few cluster nodes using Replicated Log.
常见的模式
分布式系统中的问题有非常多,上述加重的关键词都是解决特定问题的一些常见模式。下面是一个列表:
- Consistent Core
- Follower Reads
- Generation Clock
- Gossip Dissemination
- HeartBeat
- High-Water Mark
- Hybrid Clock
- Idempotent Receiver
- Lamport Clock
- Leader and Followers
- Lease
- Low-Water Mark
- Paxos
- Quorum
- Replicated Log
- Request Pipeline
- Segmented Log
- Single Socket Channel
- Singular Update Queue
- State Watch
- Two Phase Commit
- Version Vector
- Versioned Value
- Write-Ahead Log
分布式一致性
如何理解一致性:
狭义就是相等:两个副本,数据一致,就是数据是同一状态
广义是系统宏观处于一致性状态:这里我认为可以涵盖数据库的ACID中的一致概念,A向B转账,系统金钱的总和是不变的,这个是系统宏观的一致性。即所有分布式节点达到一个期望的整体状态。
系统的宏观一致性如何实现呢?就是通过分布式事务,保证多个操作在多个节点上都成功。所以我们在聊分布式事务和分布式一致性的时候,往往是混在一起的。
狭义的一致性是如何实现呢?其实总的就那么几种机制:
- 借助一致性算法
- 借助共享存储
- 借助第三方服务,例如ZK
分类:
- 弱一致性
- 强一致性
- 最终一致性
Master–Slave(leader-followers)方案:
Select one server amongst the cluster as leader. The leader is responsible for taking decisions on behalf of the entire cluster and propagating the decisions to all the other servers.
Every server at startup looks for an existing leader. If no leader is found, it triggers a leader election. The servers accept requests only after a leader is selected successfully. Only the leader handles the client requests. If a request is sent to a follower server, the follower can forward it to the leader server.
- 读写请求都由Master负责。
- 写请求写到Master上后,由Master同步到Slave上。(同步过程可以是master push,也可以是slave pull)
这种方案既可以做成强一直,也可以做成最终一致性。具体看是如何设计。
选主
对于小集群:
For smaller clusters of three to five nodes, like in the systems which implement consensus, leader election can be implemented within the data cluster itself without dependending on any external system. Leader election happens at server startup. Every server starts a leader election at startup and tries to elect a leader. The system does not accept any client requests unless a leader is elected.
- Zab
- Faft
大集群:
These large clusters typically have a server which is marked as a master or a controller node, which makes all the decisions on behalf of the entire cluster.
大集群可以直接使用外部存储ZK,etcd来帮助选主;
For electing the leader, each server uses the compareAndSwap instruction to try and create a key in the external store, and whichever server succeeds first, is elected as a leader. The elected leader repeatedly updates the key before the time to live value. Every server can set a watch on this key.
For zk:it can be implemented by trying to create a node, and expecting an exception if the node already exists.
Sample Code:
class ServerImpl…
public void startup() {
zookeeperClient.subscribeLeaderChangeListener(this);
elect();
}
public void elect() {
var leaderId = serverId;
try {
zookeeperClient.tryCreatingLeaderPath(leaderId);
this.currentLeader = serverId;
onBecomingLeader();
} catch (ZkNodeExistsException e) {
//back off
this.currentLeader = zookeeperClient.getLeaderId();
}
}Two/Three Phase Commit
引入一个协调者来管理所有的节点,负责各个本地资源的提交和回滚,并确保这些节点正确提交操作结果,若提交失败则放弃事务。
第一阶段:
协调者会问所有的参与者结点,是否可以执行提交操作。
各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写undo/redo log……
参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”。
第二阶段:
如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个Global Transaction。
如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个Global Transaction。
问题:第二阶段执行过程中数据总会存在不一致性的时刻,那么还是强一致性吗?
是,强一致性指新的数据一旦写入,在任意副本任意时刻都能读到新值。写入过程不会有严格的百分百一致性,无法保证所有节点同一时刻成功修改某一个值。
我的理解:应该尽量把繁重,容易失败的工作放在第一阶段,第二阶段尽可能的保证不会失败且执行效率高;如果第二阶段执行出现问题,往往可能需要不断重试,抛弃整个副本,或者人工介入了。
Paxos
所有一致性算法都是基于Paxos的变形。
内容:任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)
这个算法有两个阶段(假设这个有三个结点:A,B,C),
paxos中给节点赋予三个角色proposer,acceptor,learner;节点可以扮演某一个,几个,甚至全部角色;
第一阶段:Prepare阶段
A把申请修改的请求Prepare Request发给所有的结点A,B,C。注意,Paxos算法会有一个Sequence Number(你可以认为是一个提案号,这个数不断递增,而且是唯一的,也就是说A和B不可能有相同的提案号),这个提案号会和修改请求一同发出,任何结点在“Prepare阶段”时都会拒绝其值小于当前提案号的请求。所以,结点A在向所有结点申请 修改请求的时候,需要带一个提案号,越新的提案,这个提案号就越是是最大的。
如果接收结点收到的提案号n大于其它结点发过来的提案号,这个结点会一个promise(本结点上最新的被批准提案号),并保证不接收其它<n的提案。这样一来,结点上在Prepare阶段里总是会对最新的提案做承诺。
优化:在上述 prepare 过程中,如果任何一个结点发现存在一个更高编号的提案,则需要通知 提案人,提醒其中断这次提案。
注意:递增且不同的proposal id的生成是一个非常有意思的话题,有很多种方式可以实现,譬如,三个节点,他们的id分别按照这种方式递增:1,4,7.. / 2,5,8../3,6,9..,就能够满足简单的要求。
第二阶段:Accept阶段
如果提案者A收到了超过半数的结点返回的Yes,然后他就会向所有的结点发布Accept Request(同样,需要带上提案号n),如果没有超过半数的话,那就返回失败。
当结点们收到了Accept Request后,如果对于接收的结点来说,n是最大的了,那么,它就会修改这个值,如果发现自己有一个更大的提案号,那么,结点就会拒绝修改。
Zab
example:Zookeeper。ZAB协议的核⼼是 定义了对于那些会改变Zookeeper服务器数据状态的事务请求的处理⽅式
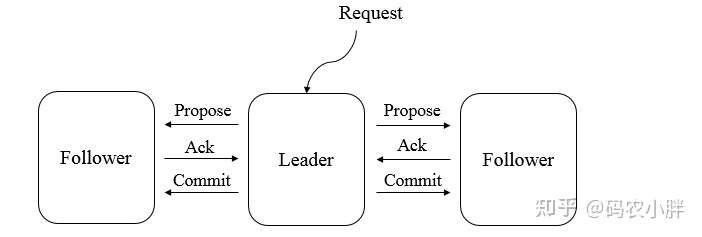
所有事务必须由一个 全局唯一的服务器来协调处理 ,这样的服务器被称为Leader服务器,余下的服务器则称为Follower服务器
- Leader服务器负责将一个客户端事务请求转化为一个事务Proposal(提案),并将该Proposal分发给集群中所有的Follower服务器
- Leader服务器等待所有Follower服务器的反馈,一旦超过半数的Follower服务器进行了正确的反馈后,Leader就会向所有的Follower服务器发送Commit消息,要求将前一个Proposal进行提交。
Raft
Bully
ES7.0之前实际上使用的是bully算法进行选主(zen discovery),之后使用基于Raft的选主策略。
PacificA
有的文章写ES使用了PacificA,但是实际上是借鉴了PacificA中的很多概念,并在此基础上ES做了适合自己的修改,譬如:
- Master维护ClusterState,其中包括了副本,节点,索引等等分布式信息
- SN,checkpoint类似与PacificA中的Serial Number和Commited Point;
选主算法
选主算法其实就是基于上述一致性算法;达成一致性的目标是确定-谁是master?