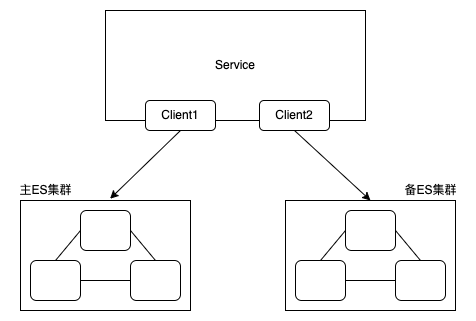
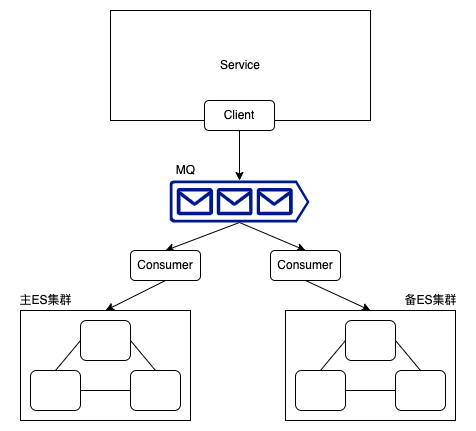
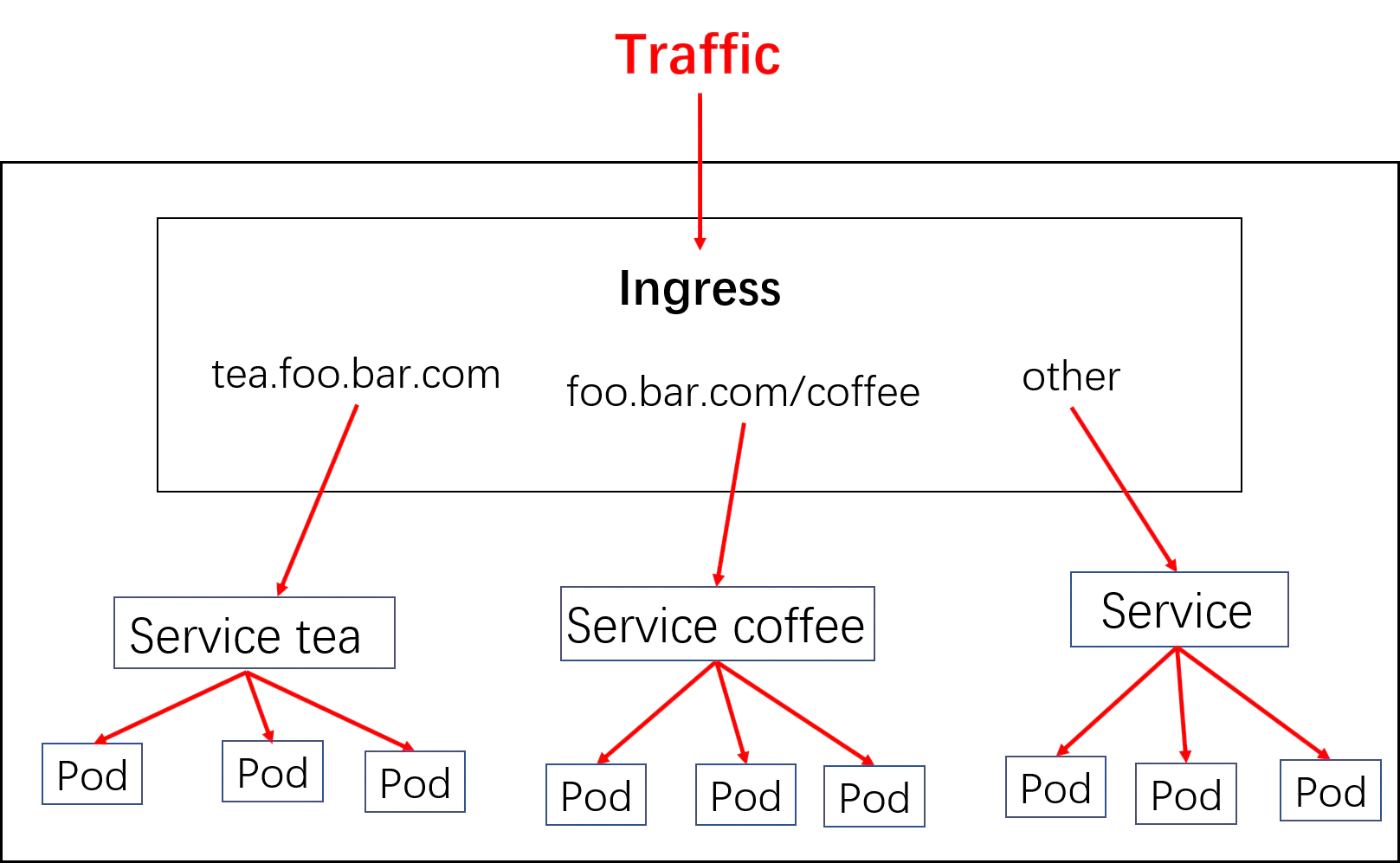
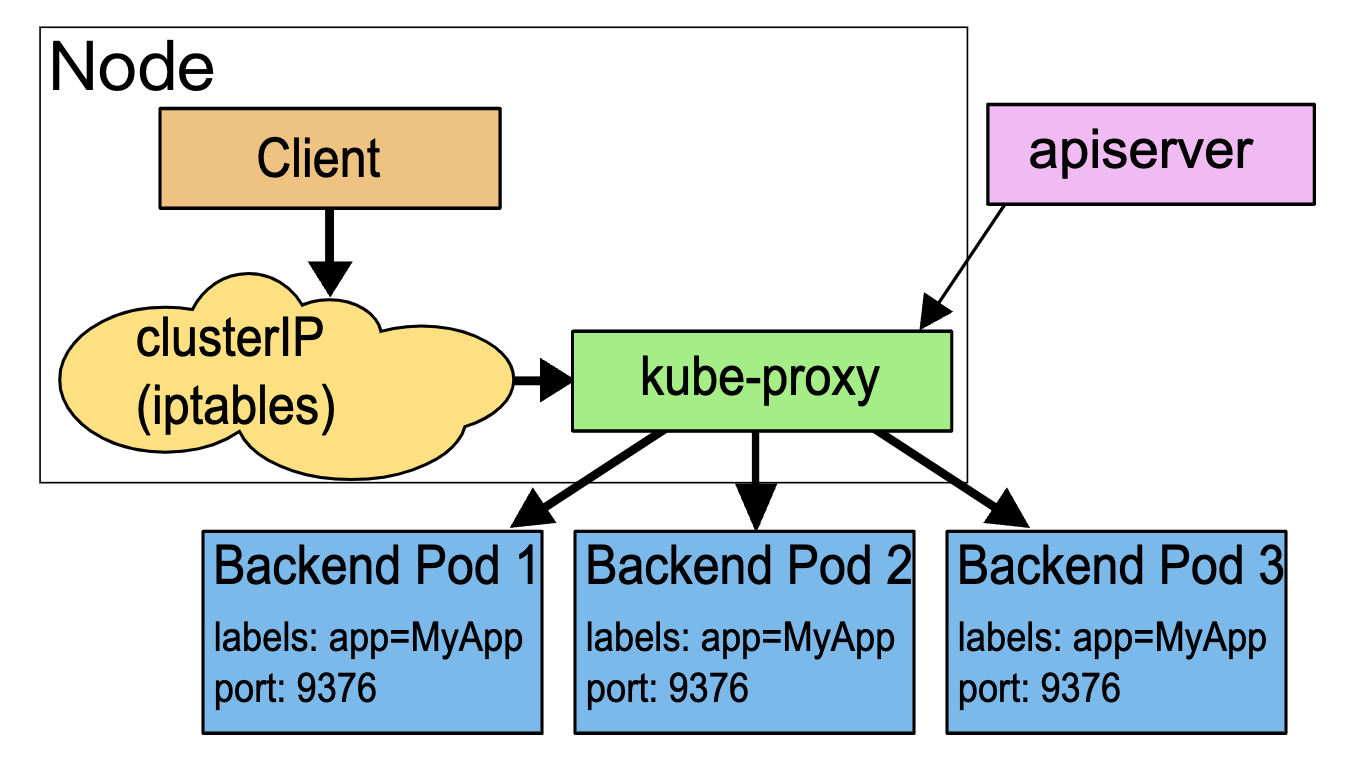
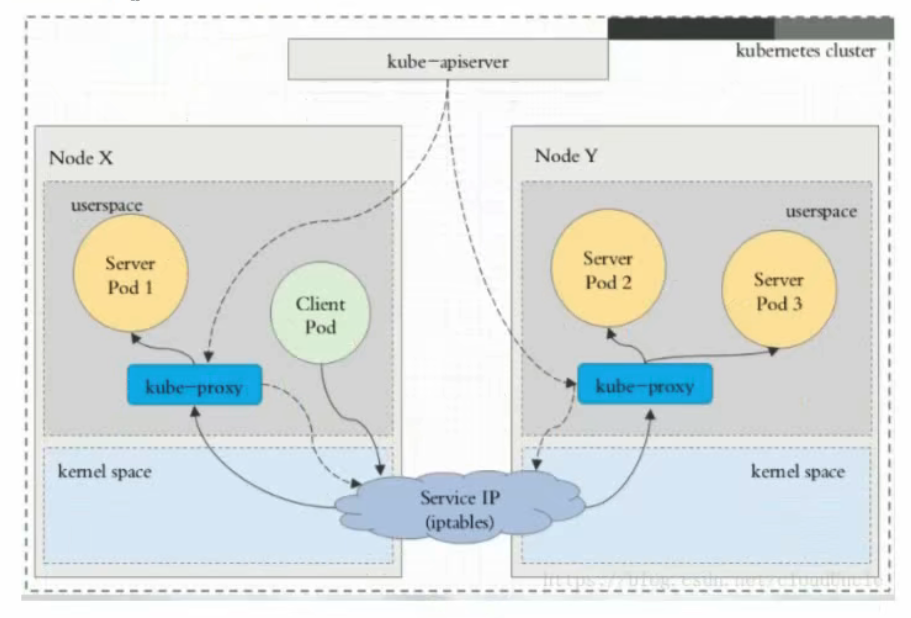
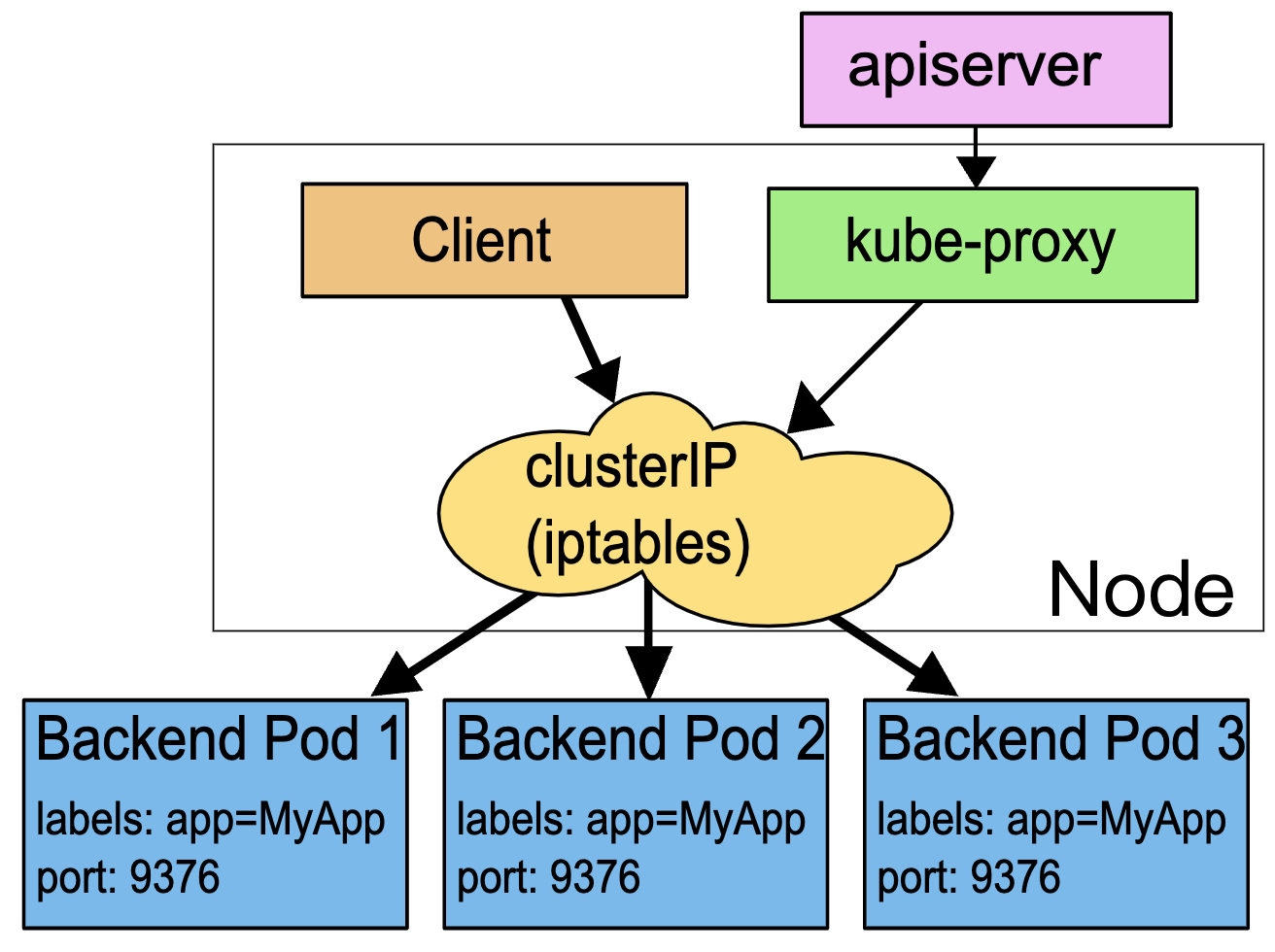
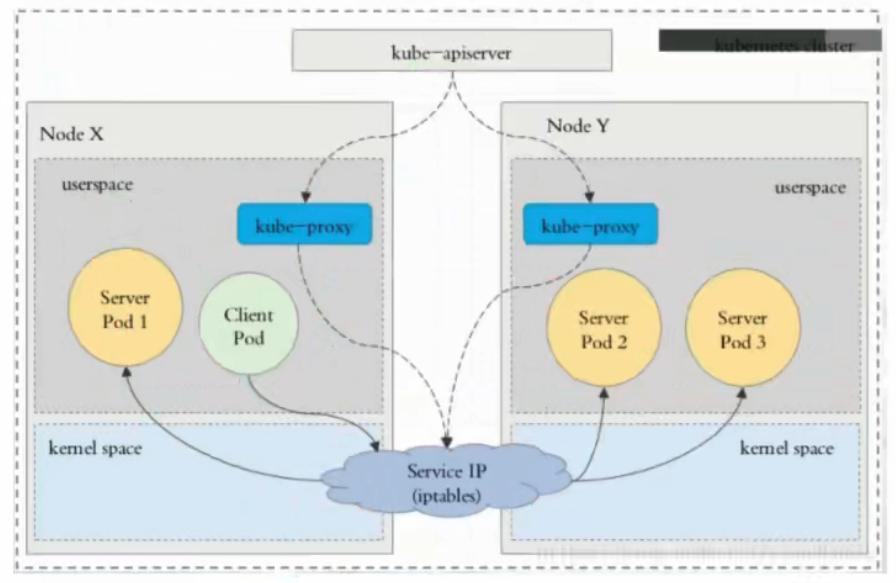
A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume.
A ConfigMap allows you to decouple environment-specific configuration from your container images, so that your applications are easily portable.
例子:
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
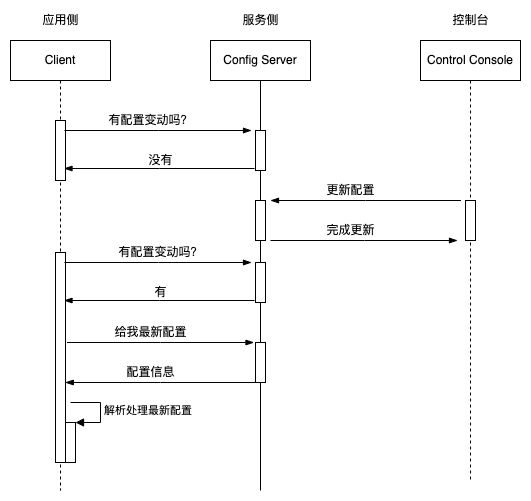
如何消费:
There are four different ways that you can use a ConfigMap to configure a container inside a Pod:
Inside a container command and args
Environment variables for a container
Add a file in read-only volume, for the application to read
Write code to run inside the Pod that uses the Kubernetes API to read a ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# Define the environment variable
- name: PLAYER_INITIAL_LIVES # Notice that the case is different here
# from the key name in the ConfigMap.
valueFrom:
configMapKeyRef:
name: game-demo # The ConfigMap this value comes from.
key: player_initial_lives # The key to fetch.
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# You set volumes at the Pod level, then mount them into containers inside that Pod
- name: config
configMap:
# Provide the name of the ConfigMap you want to mount.
name: game-demo
# An array of keys from the ConfigMap to create as files
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"
ConfigMap的更新
如果是挂载volume支持热更新
如果是env,则不支持热更新
Secret
A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in a container image. Using a Secret means that you don’t need to include confidential data in your application code.
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。 对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
容器中的进程看到的文件系统视图是由它们的 容器镜像 的初始内容以及挂载在容器中的卷(如果定义了的话)所组成的。卷挂载在镜像中的指定路径下。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
几个常用的卷类型:
Secret
Configmap
这两个不赘述,都可以挂载到pod上;
emptyDir
当 Pod 分派到某个 Node 上时,emptyDir 卷会被创建,并且在 Pod 在该节点上运行期间,卷一直存在。 就像其名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
注意:容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的
awsElasticBlockStore 卷将 Amazon Web服务(AWS)EBS 卷 挂载到你的 Pod 中。与 emptyDir 在 Pod 被删除时也被删除不同,EBS 卷的内容在删除 Pod 时会被保留,卷只是被卸载掉了。 这意味着 EBS 卷可以预先填充数据,并且该数据可以在 Pod 之间共享。
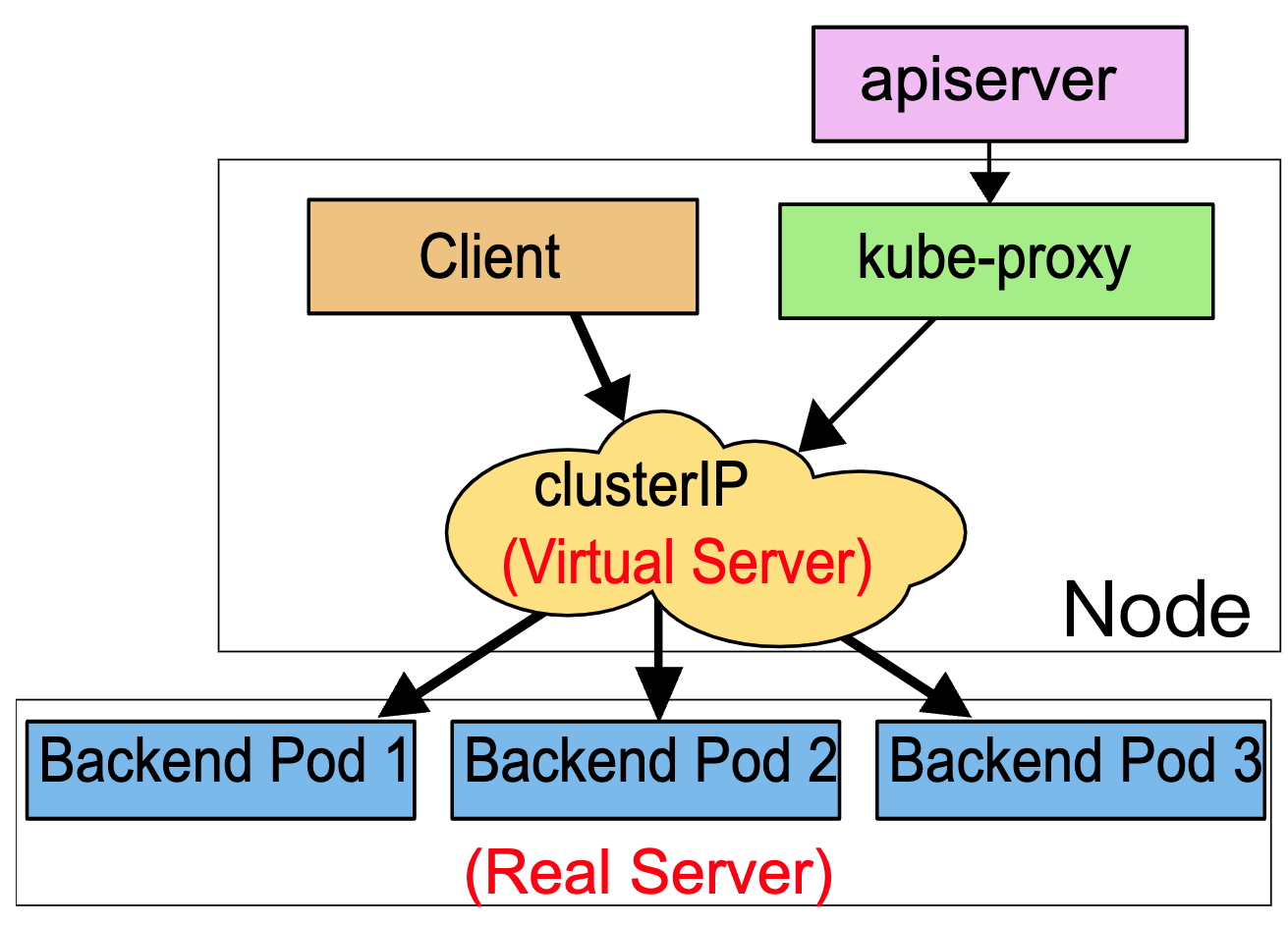
满足一个 Pod 调度请求的所有 Node 称之为 可调度节点。 如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在 未调度状态直到调度器能够找到合适的 Node。
调度的流程:过滤&打分
调度器先在集群中找到一个 Pod 的所有可调度节点(过滤),然后根据一系列函数对这些可调度节点打分(打分), 选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
也可以称这两个过程为预选和优选;
There are two supported ways to configure the filtering and scoring behavior of the scheduler:
Scheduling Policies allow you to configure Predicates(断言) for filtering and Priorities for scoring.
Scheduling Profiles(配置) 允许你配置实现不同调度阶段的插件, including: QueueSort, Filter, Score, Bind, Reserve, Permit, and others. You can also configure the kube-scheduler to run different profiles.
当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序, 并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。 因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。 如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
Pod 被创建后会进入队列等待调度。 调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。 如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。 让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。 如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
驱逐
节点压力驱逐:
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的 CPU、内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
API 发起的驱逐
API 发起的驱逐是一个先调用 Eviction API 创建 Eviction 对象,再由该对象体面地中止 Pod 的过程。
你可以通过直接调用 Eviction API 发起驱逐,也可以通过编程的方式使用 API 服务器的客户端来发起驱逐, 比如 kubectl drain 命令。 此操作创建一个 Eviction 对象,该对象再驱动 API 服务器终止选定的 Pod。
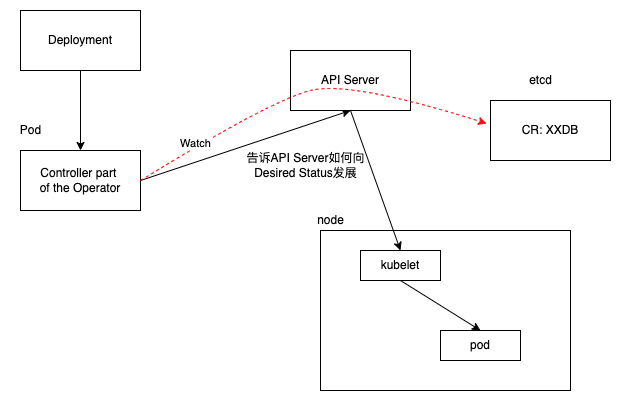
People who run workloads on Kubernetes often like to use automation to take care of repeatable tasks. The Operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides.
operator核心就是将运维操作自动化;
譬如运维人员在k8s创建一个ES集群时,有很多需要依次执行的步骤:
创建管理容器
创建master容器
创建协调节点容器
创建数据节点
创建kibana节点
等等等等
这些个步骤的自动化可以放在k8s外,当然也可以通过k8s的operator模式来实现-“operator 是一种 kubernetes 的扩展形式,可以帮助用户以 Kubernetes 的声明式 API 风格自定义来管理应用及服务,operator已经成为分布式应用在k8s集群部署的事实标准了,在云原生时代系统想迁移到k8s集群上编写operator应用是必不可少的能力”
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
Kube-Scheduler:负责调度pod到某个node上面;考虑的因素包括: individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines
有两个东西用来描述k8s中的实体:spec(资源清单)和status(状态);The Kubernetes control plane continually and actively manages every object’s actual state to match the desired state you supplied.
Namespace-名称空间:
保证对象(object)的隔离性:In Kubernetes, namespaces provides a mechanism for isolating groups of resources within a single cluster.
不同node上pod间通信有所不同:走物理网卡(src pod ip + src node ip -> dst pod ip + dst node ip)通过flannel实现
容器探针:
pod中的容器可以定义探针,可以周期性的被kubelet进行健康诊断,支持的探针类型:
容器操作
Tcp socket请求
http get 请求
静态pod:
Static Pods are always bound to one Kubelet on a specific node。kubelet直接管理的pod(而不是controller)。
容器&pod的生命周期:
pod的phase阶段:
Pending:还在schedule,下载image等等
Running:至少一个容器启动
Succeeded:所有容器都成功停止
Failed:所有容器都停止,而且至少一个是以失败状态停止的
Unknown:For some reason the state of the Pod could not be obtained. This phase typically occurs due to an error in communicating with the node where the Pod should be running.
When a Pod’s containers are Ready but at least one custom condition is missing or False, the kubelet sets the Pod’s condition to ContainersReady.
探针机制:
A probe is a diagnostic performed periodically by the kubelet on a container
探针的形式:
exec
grpc
httpGet
tcpSocket
Readiness Probe -就绪探针
检测是否ready,只有ready才会被驾到Service后面的pod列表里并提供对外服务
Liveness Probe-生存探针
检测容器是否存活
Startup Probe – 启动探针
其他探针不会在startup探针成功之前启动。
Init 容器
A Pod can have multiple containers running apps within it, but it can also have one or more init containers, which are run before the app containers are started.
Init containers are exactly like regular containers, except:
Init containers always run to completion.
Each init container must complete successfully before the next one starts.
When you set the temperature, that’s telling the thermostat about your desired state. The actual room temperature is the current state. The thermostat acts to bring the current state closer to the desired state, by turning equipment on or off.
contollers都运行在kube-controller-manager上。
A Kubernetes Controller is a routine;一个控制器本质上是一个go 协程;
Owner reference 告诉控制平面某一个对象依赖另外的哪一个对象。Kubernetes uses owner references to give the control plane, and other API clients, the opportunity to clean up related resources before deleting an object. In most cases, Kubernetes manages owner references automatically.