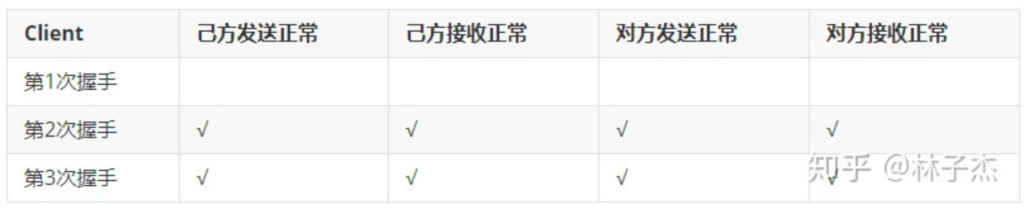
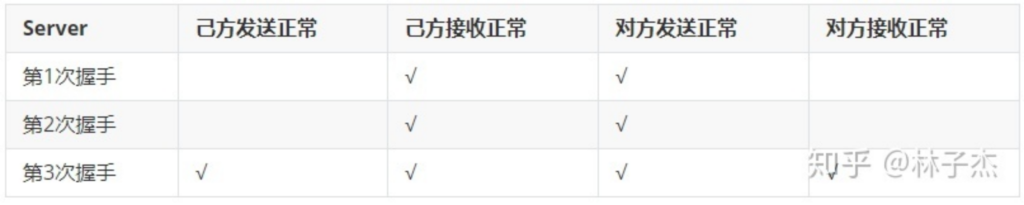
(转载请注明作者和出处‘https://fourthringroad.com/’,请勿用于任何商业用途)
基本概念
Document文档
Json 对象,由多个filed字段组成,支持多种数据类型,详见mapping
每个文档有唯一的id标识,可以指定,也可以自动生成。
元数据:_index, _type, _id, _version(每次更新都会增加), _source(原始json数据), _all(整合所有字段,不鼓励),_seq_no, _primary_term;
Index–索引
相同结构(Mapping)的文档(Document)的集合;
更好的解释:指向一个/多个分片的逻辑命名空间。
mapping相当于schema,定义字段名称和类型
Type类型:
相当于DB中的table,但是6.0之后就逐渐废弃这个概念了
Node–节点
主节点
master节点:专用/非专用
从节点
- 数据节点:
- client节点/coordinating节点:处理用户请求,转发,负载均衡
Cluster–集群:
分片shard:
- es管理文档的集合单元
- 数据的一部分
- 一个lucene index
- 包括多个segment
- 主分片:数量一旦确定不可修改
- 副本分片:主分片的拷贝,冗余备份,支持读服务
使用入门
Restful API/Kibana
curl的格式:
curl -XPUT “localhost:9200/index” -H “Content-Type: application/json” -d “{…}”
kibana的交互格式:
PUT localhost:9200/index
{…}
压测工具:esrally
常用操作:
创建索引:put /my_index
查看索引:get /_cat/indices
删除索引:delete /my_index
创建文档:
put /my_index/_doc/1 {}
put /my_index/_doc/1/_create -> 存在会报错
post /my_index/_doc {} -》 id自动生成
查询文档:
get /my_index/_doc/1
Get /my_index/_doc/_search?q=last_name:smith -> Query String搜索
Get /my_index/_doc/_search {} -> DSL(domain-specifc language) 搜索
GET /my_index/_count + DSL -> 查询符合文档数
GET /my_index/_search + _source:[“”, “”] ->source过滤,只返回感兴趣的字段
批量操作:
post _bulk -> 支持四种类型:index,create update, delete (create只创建,存在报错;index覆盖)
_mget/_msearch
集群健康:get /_cluster/health
Green/yellow/red
_cat API 集合:
update操作:
跟lucene底层类似,update操作是将文档删除,然后新建一个文档。
Update vs Index
当我们需要更新一个文档时,可以自己使用Index操作;当然也可以使用update操作,他们的底层操作是一致的,都需要删除旧文档,索引新文档。但是update的好处是:using update removes some network roundtrips and reduces chances of version conflicts between the GET and the index operation. 另外update一个大文档的部分内容,也可以节省一定的网络流量。
这里有一个ES官方开发给出的回答:
“I’m using the update API only if I have a very very big document to update. That would save a bit of network usage and memory.Otherwise, in 99,9% of the time, I’m only using the index API.”
Update by query
Updates documents that match the specified query. If no query is specified, performs an update on every document in the data stream or index without modifying the source, which is useful for picking up mapping changes.(例如增加一个子字段)
比较常见的用法是结合scripts使用:
// increments the count field for all documents with a user.id of kimchy in my-index-000001
POST my-index-000001/_update_by_query
{
"script": {
"source": "ctx._source.count++",
"lang": "painless"
},
"query": {
"term": {
"user.id": "kimchy"
}
}
}Reindex vs Snapshot Restore
“If you are doing that using the same elasticsearch major version, I believe that Snapshot/Restore is the fastest safer option.
If you are doing that from a 2.x cluster (which may be started originally with 1.x indices) to a 5.x cluster, I’d probably go to the reindex API road.”
别名-alias
(1)灵活的扩容:推荐每个人为他们的Elasticsearch索引使用别名,因为在未来重建索引的时候,别名会赋予你更多的灵活性。假设一开始创建索引只有一个主分片,之后你又决定为索引扩容。如果为原索引使用的是别名,现在你可以修改别名让其指向额外创建的新索引,而无须修改被搜索的索引之名称(假设一开始你就为搜索使用了别名)。
(2)动态的滚动查询:在实际应用中,我们也不应该向单个索引持续写入数据,知道它的分片巨大无比。巨大的索引会在数据老化后难以删除,以id为单位删除文档不会立即释放空间,删除doc只在lucene分段合并时才会真正从磁盘中删除。即使手工触发分段合并,仍会引起较高的I/O压力,并且可能因为分段巨大导致合并过程中磁盘空间不足(分段大小大于此片可用空间的一半). 因此,另外一个有用的特性是:在不同的索引创建窗口。比如,如果为数据创建了每日索引,你可能期望一个滑动窗口覆盖过去一周的数据,别名就称为last-7-days.然后,每天创建新的每日索引时,将其加入别名,同时删除第8天前的旧索引。这样,对于业务方来说,读取时使用的别名不变,当需要删除数据的时候,可以直接删除整个索引
Mapping(Schema)
指定字段(field)名称,类型,设置倒排索引相关配置。
mapping中字段类型一旦设定,就不能更改了(lucene底层是不支持修改的);如果有需求只能创建新的索引然后reindex;
如果需要扩展一个字段的功能,可以通过增加子字段,然后用update by query api进行更新。
可以通过dynamic:true/false/strict 来设定是否能够动态增加新字段
Dynamic:true时:动态mapping,es会自动识别类型,例如一个字符串:”username”:”bob”
“username”:{
“type”:”text”,
“fields”: {
“keyword”:{ //自动带keyword子字段
“type”:”keyword”,
“ignore_above”:256
}
}
}没有分词的字段也是有索引的,所以具备检索能力;
可以通过index:true/false控制一个字段是否索引,不索引的字段不可以搜索。譬如手机号,不希望被搜索;同时也可以节省大量存储空间。
_all字段和copy_to操作:
_all字段由所有字段内容拼接而成,方便统一查询,但是已经被废弃;可以给一个字段加copy_to配置,使得自动将它copy到某一个字段,后者可以扮演类似_all的角色。
数据类型
- 简单数据类型
- 字符串:text,keyword
- 数值型:long,integer,short,byte,double,float。。。
- 布尔:boolean
- 日期:date
- 二进制:binary
- 范围类型:integer_range, float_range, long_range…
- 复杂数据类型:
- 数组:array
- 对象:object
- 嵌套对象:nested object
- 地理位置:geo_point,geo_shape
多字段特性(multi-fields特性):通过不同的方法索引相同的字段;譬如同时使用keyword和text索引一个字段,这样既可以全文检索,也可以keyword查询
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}可以直接使用city.raw来使用
多字段的另一个应用场景是使用不同的方法分析相同的字段以求获得更好的相关性。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
}Numeric_detection:true 可以开启数字的自动探测(“xx”:”num”),而不是默认的text
Date支持自定义格式的自动探测
动态模版–dynamic template
动态模板允许你定义可以用于动态添加的字段的自定义映射,可实现效果例如:
- 所有的字符串类型都设定称 Keyword,或者关闭 keyword 字段
- is 开头的字段都设置成 boolean
- long_ 开头的都设置成 long 类型
匹配方式:
- 匹配类型
- 匹配名称
- 匹配路径(对象结构)
PUT my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}
}索引模版–index template
创建索引时自动生成预定义的mapping和settings
如果index同时命中两个模版,order大的会覆盖order小的属性(局部覆盖)。
Sample:(下面格式低版本和高本本有所不同)
PUT _template/template_1
{
"index_patterns": ["te*", "bar*"],
"template": {
"settings": {
"number_of_shards": 1
},
"mappings": {
"_source": {
"enabled": true
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
},
"aliases": {
"mydata": { }
}
},
"priority": 500,
"composed_of": ["component_template1", "runtime_component_template"],
"version": 3,
"_meta": {
"description": "my custom"
}
}快照原理
https://www.cnblogs.com/dyfblog/p/15220301.html
倒排索引
正排索引:文档ID指向内容;例如书籍的目录-文章名称指向文章内容所在位置
倒排索引:关键词指向文档ID;例如书籍的索引页-关键词指向文章的名称
Sample:
Term/token doc1 doc2
Bring y n
Home y y
White n y
Fox y n如何构建倒排索引:将文章内容分词,并与文章ID进行关联
搜索引擎的逻辑:
- 将搜索key进行分词
- 用分词去倒排索引查找文章
- 按照关联程度返回给用户
构成
单词词典(Term Dictionary)
有很多结构适合快速的查询B+tree, HashMap, 单词词典采用FST,类似于字典树trie。提供单词的快速查询,并记录了单词到倒排列表的关联信息。
https://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/
倒排列表(Posting List)
- 文档ID
- 单词频率(TF,Term Frequency)
- 位置Position:文档分词后的位置
- 偏移Offset:记录在文档的开始和结束位置,用于高亮
es中每个字段都会有自己的倒排索引
分词
将文本转化为term/token的过程,es中叫Analysis
分词器–Analyzer
构成:
- Character Filter:对原始文本过滤处理,例如去掉html特殊符号
- Tokenizer:切分单词
- Token Filter: 对单词处理:譬如转小写,删除/增加等等
可以基于上面三个环节进行自定义分词:
PUT my_index
{
“settings”: {
“analysis”:{
对三个环节进行自定义或指定一个三方分词器
}
}
}常用分词器:
- Standard
- Simple
- WhiteSpace
- Stop
- IK:中文分词器
- 支持自定义词库
- 热更新分词词典
- 结巴:中文分词器
- 更高阶的是基于自然语言处理的分词器
分词分析API:Analyze API
可以指定分词器,自定义分词器构成等等
例如:
POST _analyze
{
“analyzer”:”standard”,
“text”:”xxxxx”
}如何重新索引你的数据:
一旦创建索引,就不能修改分析器/改变现有字段,否则会造成已经索引的数据无法正常搜索,需要重新索引数据,有两个方式:
- Reindex API
- 用scroll API从旧索引批量读取文档,然后使用bulk api重新index所有数据
检索Search
GET /my_index/_search
两种格式
- URI search(query string)
- Query DSL(body体)
Query DSL:
基于json格式定义
GET /my_index/_search
{
“query”:{
“term”: xxxxxx
}
}- 查询时加上profile:true 参数可以打印es查询的的过程
- 查询时加上explain:true 参数可以查看算分的详细内容
- Validate API 也可以对查询请求进行验证,检查lucene底层执行的语句是什么
相关性算分 :解决返回文档排序
- 词频:Term Frequency:频率越大,相关性越高
- 文档频率:Document Frequency:出现文档越少,相关性越高
- Inverse Document Frequency(IDF): 1/文档频率
- Filed-length Norm:文档越短,相关性越高
两个模型:
- TF/IDF 模型:
- 与TF, IDF,成正比,
- 文档长度成反比
- BM25模型:5.x之后默认的模型
- 基于TF/IDF进行了优化
分类:
- 字段类查询,只针对一个字段进行查询
- 复合查询:针对一个或者多个字段
字段类查询
全文匹配:针对text类型的字段进行全文检索,需要对插叙语句进行分词
- Match query
- Match Phrase Query:在match基础上有term顺序要求
- Query String Query:多字段,多关键字(支持AND,OR,NOT等语句支持)
单词匹配:不分词,直接匹配倒排索引
- Term Query:不对查询语句进行分词;精确查询,适合检索非text类型的字段,比如keyword 、numeric、date;需要注意,拿term去查text要尤其注意分词问题。
- Terms Query:针对多个term
- Range Query:主要这对数字,date
复合查询
- Constant_score Query:可以实现自定义得分
- Bool query:包含多个bool子句,每个子句其实就是上面的字段类查询
- Filter:过滤符合条件的文档,不计算相关性得分(提高查询效率)
- Must:必须符合条件,计算相关性得分
- Must_not:与filter相反;也不会计算相关性得分,起到一个过滤效果
- Should: 计算相关性得分
Search的Query–Then–Fetch过程
- Query:协调节点收到一个search请求,选择分片,发送search请求;这些分片会返回指定个数(from+size)个文档ID和排序值用于排序,最后综合得到from+size个文档ID
- Fetch:协调节点接着根据文档的ID向分片发送_mGet请求,获得文档的详细内容;协调节点拼接后返回给用户;
相关性算分问题:
同一条文档在不同shard上会得到不同的相关性分数(因为shard之间是独立的,甚至在不同的节点上),有时候会导致一些排序不准确的问题。
Dfs_query_then_fetch可以解决这个问题(拿到所有文档后重新计算分数),但是非常耗费资源。
排序,fielddata 和 doc_values
默认使用相关性算分的结果进行排序,用户也可以用自定义的方式进行排序:
get my_index/_search
{
“sort”:[
{“xx_field”:”asc/desc”},
{“_score”:”asc/desc”}, // 与相关性算分结合
{“yy_field”:”asc/desc”},
...
]
}多个条件按顺序判断;
这里的field可以是keyword,date,integer等类型,但是如果是text的话会报错:
Fielddata is disabled on text fields by default
原因是text的类型在索引中是以分词形态存在的,只有设置fielddata=true才能够获取到text字段的所有值,缺点是会占用大量的空间。也可以将text字段改成keyword类型。
doc_values是什么:一个列式存储映射
为了加快排序、聚合操作,在建立倒排索引的时候,额外增加一个列式存储映射,是一个空间换时间的做法。默认是开启的,对于确定不需要聚合或者排序的字段可以关闭。
- 在ES保持文档,构建倒排索引的同时doc_values就被生成了, doc_values数据太大时, 它存储在电脑磁盘上.
- doc_values是列式存储结构, 它擅长做聚合和排序
- 对于非分词字段, doc_values默认值是true(开启的), 如果确定某字段不参与聚合和排序,可以把该字段的doc_values设为false
- 例如SessionID, 它是keyword类型, 对它聚合或排序毫无意义, 需要把doc_values设为false, 节约磁盘空间
- 分词字段不能用doc_values
两种获得field字段值的方式:(本质就是ID-》field信息)
- Fielddata, 默认对所有字段都是禁用的,所以text在开启fielddata之后可以获得字段值。在搜索时创建,位于内存之中。
- Doc values,除了text类型之外,都默认启用的。会在index文档是时创建,存储在磁盘。
如何开启fielddata:在相应的text字段的mapping中append-> fielddata:true
如何关闭doc values:在non-text字段mapping中append->doc_values:false
关闭之后lucene底层就不会存这个字段了,之后再打开必须要reindex才行
分页 & 遍历
From + size
深度分页问题:如果from=4980,size=20,有五个分片;那么每个分片都需要取5000条数据,并且在协调节点汇总排序,对内存压力非常大;
ES默认有限制深度分页条数为10000;
Scroll
解决深度分页的问题
Get my_index/_search?scroll=10m {size:10} ->返回一个_scroll_id,后序可以迭代_scroll_id,不断的向后查询;
POST _search/scroll
{
scroll:10m, //续10分钟
scroll_id:xxxx
}原理是创建一个用于查询的快照:
- 有有效时间设定
- 有翻页数量设定
- 不具备搜索实时性,创建快照后的新文档无法查询到
- 创建快照会消耗一定时间和资源(尤其是内存)
Search After
解决深度分页的问题
在每次搜索时指定search after = 上次搜索最后一条记录的得分
这样在每一个分片上只需要搜索size条记录,汇总之后在协调节点排序返回
实时性好,但是只能向后翻页
Aggregation-聚合分析(统计分析)
ES的基本功能是查询检索,在此基础上,还可以进行针对ES查询的的数据结果做统计分析
GET /my_index/_search
{
“query”:{}
//聚合分析会对query的结果进行分析
“aggs”:{
name
type
body //提供这个type需要的参数
aggs //子聚合分析
...
//可以包含多个上述结构体,即多个聚合查询
name
type
body //提供这个type需要的参数
aggs //子聚合分析
}
}基本类型
- Metric,指标分析,max,min,avg
- Bucket:分桶,类似SQL中的GroupBy
- Pipeline,冠道,基于前序聚合分析结构继续计算
- Matrix,矩阵分析类型
Metric
- Min:返回数值类字段最小值
- Max
- Avg
- Sum
- Cardinality:基数,等同 distinct+count
- Stats: count,min,max,avg,sum 多个数据集成
- Extended_stats: Stats的拓展,包括方差,标准差等等信息
- Percentiles:百分位数统计,可以统计数据的分布情况
- Top_hits: 通常配合分桶使用,作为子查询,用于获取桶内顶部size个记录的详细内容
Bucket
按照一定规则分桶
- Terms:按照keyword分桶(如果是text类型会按照分词进行分桶)
- Range/data range:0-100,100-200,200-300 。。。等 /按日期分桶
- Histogram/date Histogram:直方图,按照固定单位分割
支持嵌套子查询,即分桶之后再分桶;
也可以Bucket配合Metric嵌套查询;
Pipeline:
在聚合分析的结果之上执行一些操作:
例如,我对数据分桶,然后计算metrics,再对metric进行一些操作。
- Min_bucket: 求桶的某个指标最小值
- Max_bucket
- Avg_bucket
- Sum_bucket
- Stats_bucket: 对之前的聚合分析的结果做stat分析
- Percentiles_bucket
- Derivative: 按桶的某个指标求导数来分析走向
- Moving_avg: 移动平均值
- Cumulative_sum: 累计求和
修改作用范围:
- Filter:过滤掉一部分数据后再做聚合分析
- Post-Filter:在聚合分析结束后,过滤结果
- Global:不基于query结果,在全量数据里查询
对桶排序
默认排序是根据桶内的数据量(_count)
Order:
- 可以按照某个指标进行排序,例如_count
- 可以按照子聚合中的数值排序
注意:query语句里面对结果是通过sort来进行的
聚合查询底层执行逻辑
ES的聚合查询结果排名可能不是准确的!
我们在有的聚合查询时(例如分桶)通常会指定最终返回的数据量:size=xx;es在返回结果时,会按照count(桶中数据量)进行排序,然后返回前size个;
- 大部分情况是协调节点到每个分片所在节点上分别获得聚合值,再统一在协调节点计算返回给用户的值
- 因为从每个节点都是按贪心来取数据,比如需要top 3,就从每个shard取top3,再到协调节点进行贪心计算,获得全局top3;所以最终返回的数据不一定准确;解决方案是设定shard_size大于最终需要的数据量;这样协调节点会过量的从每个shard上取得需要的数据,再做排序。
- 衡量shard_size指标合理性的标准是,每个桶的 doc_count_error_upper_bound 尽可能接近0;
海量数据,准确度,实时性很难三者都得到满足,例如hadoop,spark离线计算方案可以处理海量数据,准确度高,但是实时性差;mysql等关系型数据库实时性,准确度高,但是处理数据量有限;es的某些聚合统计就是满足了实时性,海量数据,但是准确度不能得到满足;可以通过调参提高准确度,但是实时性也会相应的下降。
高级功能–ES Scripts
在Elasticsearc中,它使用了一个叫做Painless的语言。它是专门为Elasticsearch而建立的。Painless是一种简单,安全的脚本语言,专为与Elasticsearch一起使用而设计。 它是Elasticsearch的默认脚本语言,可以安全地用于inline和stored脚本。它具有像Groovy那样的语法。自Elasticsearch 6.0以后的版本不再支持Groovy,Javascript及Python语言。
例子:
如何避免了从客户端发起多次查询与写入:
PUT twitter/_doc/1
{
"user" : "双榆树-张三",
"message" : "今儿天气不错啊,出去转转去",
"uid" : 2,
"age" : 20,
"city" : "北京",
"province" : "北京",
"country" : "中国",
"address" : "中国北京市海淀区",
"location" : {
"lat" : "39.970718",
"lon" : "116.325747"
}
}
//将age修改成30
POST twitter/_update/1
{
"script": {
"source": "ctx._source.age = 30"
}
}scripts可以被存放于一个集群的状态中。它之后可以通过ID进行调用:
PUT _scripts/add_age
{
"script": {
"lang": "painless",
"source": "ctx._source.age += params.value"
}
}
//调用
POST twitter/_update/1
{
"script": {
"id": "add_age",
"params": {
"value": 2
}
}
}分布式架构
TBD 架构图
Cluster State信息
- node级别state信息
- index级别state信息,
- shard级别state信息,
都分别保存在各自独立的目录下,其中index级别的state信息在7.x版本中被合并到node级别state同一个目录下。
ClusterState在每个节点上其实都维护了一份(mem+disk),通过event-driven形式进行更新。
Master 节点
Master节点负责管理Cluster State信息;后者存储在各自节点上,Master维护最新版本并且同步到不同的节点
在云上我们通常会有一个master专用集群,由三个master-eligible节点构成;但是同一时间只会有一个master
Master的一致性算法采用的是:2-Phase-Commit算法TBD
Coordinating协调节点
处理用户请求,将请求分发到master/数据节点;
默认每个ES节点都具备扮演协调节点的能力;
云上通常会有专用的协调节点集群,防止数据节点/master节点耗费过多资源在处理网络请求上。Bulk操作,agg操作等都会对coordinating产生压力。也能充分利用专用协调节点的优势。
文档到分片的映射算法
Shard ID= hash(routing_id)%主分片数量
Routing_id在put请求时,可以人为指定,也可以使用默认值(文档ID);
Shard的底层架构
Shard对应的其实就是Lucene的Index
Lucene文件系统是不可修改的(只能追加和读),所以shard从本质上也是不可修改的;
Page Cache缓存的的利用:
CPU如果要访问外部磁盘上的文件,需要首先将这些文件的内容拷贝到内存中,由于硬件的限制,从磁盘到内存的数据传输速度是很慢的,如果现在物理内存有空余,干嘛不用这些空闲内存来缓存一些磁盘的文件内容呢,这部分用作缓存磁盘文件的内存就叫做page cache. 用户进程启动read()系统调用后,内核会首先查看page cache里有没有用户要读取的文件内容,如果有(cache hit),那就直接读取,没有的话(cache miss)再启动I/O操作从磁盘上读取,然后放到page cache中,下次再访问这部分内容的时候,就又可以cache hit,不用忍受磁盘的龟速了(相比内存慢几个数量级)。
同时因为Lucene文件系统是不可修改的,缓存是不需要更新的;
几个重要节点:
- 生成倒排索引文件(segment)
- 更新Commit Point文件:segments_N文件
- 更新.del文件
Refresh:
对应Lucene的flush,将内存中Buffer(lucene中的数据结构)里的数据生成segment,但是不保证落盘;
ES refresh的频率默认是1s;
会更新Commit Point文件:segments_N文件 -> 数据结构SegmentInfos
高版本里面refresh的时机有所改变,如果没有搜索,并不会保持持续的更新;
Flush:
对应Lucene的commit,操作系统的fsync;
flush操作包括:refresh,更新commit point, fsync,清除translog
flush时机:Flush happens automatically depending on how many operations get added to the transaction log, how big they are, and when the last flush happened.
Translog- Transaction Log
Changes to Lucene are only persisted to disk during a Lucene commit, which is a relatively expensive operation and so cannot be performed after every index or delete operation. Changes that happen after one commit and before another will be removed from the index by Lucene in the event of process exit or hardware failure.
Lucene commits are too expensive to perform on every individual change, so each shard copy also writes operations into its transaction log known as the translog. All index and delete operations are written to the translog after being processed by the internal Lucene index but before they are acknowledged. In the event of a crash, recent operations that have been acknowledged but not yet included in the last Lucene commit are instead recovered from the translog when the shard recovers.
An Elasticsearch flush is the process of performing a Lucene commit and starting a new translog generation. Flushes are performed automatically in the background in order to make sure the translog does not grow too large, which would make replaying its operations take a considerable amount of time during recovery. The ability to perform a flush manually is also exposed through an API, although this is rarely needed.
写入translog的频率也是可以调整的;默认每一个操作都会写;
删除&更新文档
lucene是不可修改的,底层维护一个.del文件记录所有删除文档的ID,查询结果返回前会利用.del文件内容进行过滤
段合并–segment merge
在可以是ES自动触发,也可以是用户手动触发
ES分布式设计关键点
- 满足CAP理论
- Meta data的一致性
- Primary/Replication 分片的一致性
- Master的选主过程设计
- Sequence Number设计
- Primary Term设计
- Lucene软删除的设计
- 基于事件驱动的设计思想
- 写流程分析
- 读流程分析
- 批量操作分析: Bulk/mget/msearch
- 脑裂问题避免 – quorum
- translog机制
- Pacific-A算法的应用
ES的一些设计思想
- 通过分布式保证扩展性,能处理更大量的数据
- 通过分布式保证系统HA
- 通过不同角色的专用节点,提高资源使用效率,保证系统的稳定性
- 通过引入主分片保证数据容量
- 通过副本分片保证数据的HA
写一致性中的quorum的概念
2.4 version
Write Consistency
To prevent writes from taking place on the “wrong” side of a network partition, by default, index operations only succeed if a quorum (>replicas/2+1) of active shards are available. This default can be overridden on a node-by-node basis using the action.write_consistency setting. To alter this behavior per-operation, the consistency request parameter can be used.
Valid write consistency values are one, quorum, and all.
Note, for the case where the number of replicas is 1 (total of 2 copies of the data), then the default behavior is to succeed if 1 copy (the primary) can perform the write.
The index operation only returns after all active shards within the replication group have indexed the document (sync replication).
Index operation return when all live/active shards have finished indexing, regardless of consistency param. Consistency param may only prevent the operation to start if there are not enough available shards(nodes).
Stackoverflow 文章
There is a write consistency parameter in elasticsearch as well, but it is different compared to how other data storages work, and it is not related to whether replication is sync or async. With the consistency parameter you can control how many copies of the data need to be available in order for a write operation to be permissible. If not enough copies of the data are available the write operation will fail (after waiting for up to 1 minute, interval that you can change through the timeout parameter). This is just a preliminary check to decide whether to accept the operation or not. It doesn’t mean that if the operation fails on a replica it will be rollbacked. In fact, if a write operation fails on a replica but succeeds on a primary, the assumption is that there is something wrong with the replica (or the hardward it’s running on), thus the shard will be marked as failed and recreated on another node. Default value for consistency is quorum, and can also be set to one or all.
5.0及以上:
Active shardsedit
To improve the resiliency of writes to the system, indexing operations can be configured to wait for a certain number of active shard copies before proceeding with the operation. If the requisite number of active shard copies are not available, then the write operation must wait and retry, until either the requisite shard copies have started or a timeout occurs. By default, write operations only wait for the primary shards to be active before proceeding (i.e. wait_for_active_shards=1). This default can be overridden in the index settings dynamically by setting index.write.wait_for_active_shards. To alter this behavior per operation, the wait_for_active_shards request parameter can be used.
Valid values are all or any positive integer up to the total number of configured copies per shard in the index (which is number_of_replicas+1). Specifying a negative value or a number greater than the number of shard copies will throw an error.
For example, suppose we have a cluster of three nodes, A, B, and C and we create an index index with the number of replicas set to 3 (resulting in 4 shard copies, one more copy than there are nodes). If we attempt an indexing operation, by default the operation will only ensure the primary copy of each shard is available before proceeding. This means that even if B and C went down, and A hosted the primary shard copies, the indexing operation would still proceed with only one copy of the data. If wait_for_active_shards is set on the request to 3 (and all 3 nodes are up), then the indexing operation will require 3 active shard copies before proceeding, a requirement which should be met because there are 3 active nodes in the cluster, each one holding a copy of the shard. However, if we set wait_for_active_shards to all (or to 4, which is the same), the indexing operation will not proceed as we do not have all 4 copies of each shard active in the index. The operation will timeout unless a new node is brought up in the cluster to host the fourth copy of the shard.
It is important to note that this setting greatly reduces the chances of the write operation not writing to the requisite number of shard copies, but it does not completely eliminate the possibility, because this check occurs before the write operation commences. Once the write operation is underway, it is still possible for replication to fail on any number of shard copies but still succeed on the primary. The _shards section of the write operation’s response reveals the number of shard copies on which replication succeeded/failed.
关于lucene
lucene文件类型
Name Extension Brief Description
Segment Info .si segment的元数据文件
Compound File .cfs, .cfe 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息
Fields .fnm 保存了fields的相关信息
Field Index .fdx 正排存储文件的元数据信息
Field Data .fdt 存储了正排存储数据,写入的原文存储在这
Term Dictionary .tim 倒排索引的元数据信息
Term Index .tip 倒排索引文件,存储了所有的倒排索引数据
Frequencies .doc 保存了每个term的doc id列表和term在doc中的词频
Positions .pos Stores position information about where a term occurs in the index
全文索引的字段,会有该文件,保存了term在doc中的位置
Payloads .pay Stores additional per-position metadata information such as character offsets and user payloads
全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性
Norms .nvd, .nvm 文件保存索引字段加权数据
Per-Document Values .dvd, .dvm lucene的docvalues文件,即数据的列式存储,用作聚合和排序
Term Vector Data .tvx, .tvd, .tvf Stores offset into the document data file
保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用
Live Documents .liv 记录了segment中删除的doclucene中的数据类型
我理解lucene中的数据类型跟es中的数据类型是有映射关系:
https://lucene.apache.org/core/7_3_1/core/index.html?org/apache/lucene/document/FieldType.html
- BinaryDocValuesField
- BinaryPoint
- DateTools
- Document
- DocumentStoredFieldVisitor
- DoubleDocValuesField
- DoublePoint
- DoubleRange
- Field
- FieldType
- FloatDocValuesField
- FloatPoint
- FloatRange
- IntPoint
- IntRange
- LongPoint
- LongRange
- NumericDocValuesField
- SortedDocValuesField
- SortedNumericDocValuesField
- SortedSetDocValuesField
- StoredField
- StringField
- TextField
功能细节
磁盘水位保护:
- Low watermark:85不分配
- High watermart:90 reroute
- 95-> readonly
控制面功能
- 功能类似:kibana/cerebro
- 集群状态查看
- 索引状态查看
- 分片大小及分布查看
- 模版管理
- snapshot管理
- settings管理
- mapping管理
- alias管理
- analyze工具
- 智能诊断工具
- 监控面板
FAQ
ES存在脏读吗(读未提交)?
不存在;可能存在读取primary的数据还没有同步到replica,但是ES底层lucene是不可修改的文件系统,不存在回滚,并且ES是非实时系统,所以不存在脏读的问题。
文章
一致性分析:
ES底层数据存储:
https://elasticsearch.cn/article/6178
Lucene 操作: